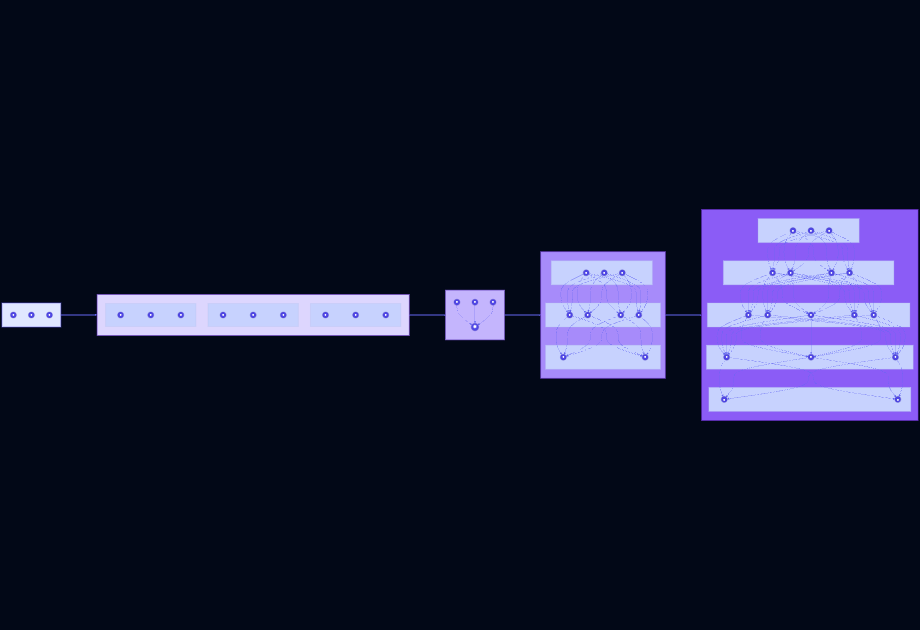
Foundations of AI: From Vectors to Neural Networks
Disclaimer: I am still learning some of the concepts covered in this article, and it was written with the help of AI. As a result, it may contain inaccuracies or mistakes. If you spot any errors, feel free to reach out so I can correct them.
Modern artificial intelligence is built on a mathematical foundation that might seem intimidating at first, but whose core concepts are surprisingly accessible. This comprehensive guide will take you through each building block, showing how they connect and culminate in the sophisticated architectures powering today’s AI systems.
The Journey in Brief
Imagine starting with a simple language for representing information—vectors, which are just ordered lists of numbers, and matrices, which transform these lists from one form to another. These mathematical objects became our toolkit for representing everything: images as pixel vectors, words as meaning vectors, and entire sequences as matrix transformations. Each dot product between vectors tells us how similar two things are—like comparing “cat” and “dog”—and each matrix multiplication reshapes information, letting us build increasingly sophisticated transformations step by step.
With this foundation, we discovered how to make these mathematical systems learn by themselves. Neural networks emerged as chains of these transformations, where each layer learns increasingly abstract patterns: early layers might detect edges, while later layers recognize entire objects. The magic of learning happens through gradients—mathematical compasses that point in the direction of improvement. By following these gradients downward (gradient descent), the network continually adjusts its millions of parameters to reduce its errors, gradually discovering patterns no human could explicitly program.
But there was still a missing piece: how to represent discrete symbols like words in a way that captured their meaning. This led to embeddings—learning to map words into dense vectors where similar meanings cluster together in space. Suddenly, arithmetic on words revealed relationships: “king” minus “man” plus “woman” equals approximately “queen.” This breakthrough unlocked attention mechanisms, which let models dynamically focus on different parts of their input when producing each piece of output—like paying attention to “cat” when translating “gato,” rather than trying to remember everything in one fixed summary.
Finally, attention evolved into transformers, which revolutionized AI by processing entire sequences in parallel through self-attention. Each position queries the others (“what information do I need?”), receives responses weighted by relevance, and combines them into rich, context-aware representations. This elegant architecture—built entirely from the simple mathematics of vectors, matrices, gradients, and attention—powers today’s most capable AI systems, from language models that write poetry to image generators that create art. The journey from basic linear algebra to attention-based transformers reveals a beautiful story: profound capabilities emerging from carefully composed mathematical foundations.
We’ll progress through four phases:
- Mathematical Foundations: Linear algebra, probability, and calculus
- Optimization: Loss functions and gradient descent
- Neural Networks: Perceptrons, activations, and backpropagation
- Advanced Architectures: Attention, transformers, and embeddings
By the end, you’ll have a complete understanding of how these pieces fit together to create systems that can learn from data and perform remarkable tasks.
Phase 1: Introduction
Introduction
Modern AI and deep learning are built on a foundation of mathematics that might seem intimidating at first, but the core concepts are surprisingly accessible. This series will guide you through the mathematical foundations, showing how each piece connects to the next, until we arrive at the sophisticated architectures powering today’s AI systems.
Phase 1: The Mathematical Language
Notation and Vocabulary
Before diving into the math, let’s establish a common vocabulary. In machine learning and neural networks, you’ll frequently encounter:
- Scalars: Single numbers (e.g., )
- Vectors: Ordered lists of numbers, denoted as
- Matrices: 2D arrays of numbers, denoted as
- Functions: Mappings from inputs to outputs,
- Parameters: Values we learn during training (weights, biases)
This notation becomes our shared language for describing computations in neural networks.
Linear Algebra: Vectors and Matrices
Linear algebra is the workhorse of machine learning. Every computation in a neural network can be expressed as operations on vectors and matrices.
Vectors represent data points. For example, an image with 784 pixels can be represented as a vector .
Matrices represent transformations. A weight matrix transforms an -dimensional input into an -dimensional output.
Key operations:
- Vector addition:
- Scalar multiplication:
- Dot product:
- Matrix multiplication:
The dot product is particularly important—it measures similarity between vectors and is the fundamental operation in neural networks.
Why it matters: Neural networks transform data through sequences of linear transformations (matrix multiplications). Understanding these operations helps us understand what the network is learning.
Basic Probability: Random Variables and Distributions
Neural networks operate in a world of uncertainty. Probability theory gives us tools to model and reason about this uncertainty.
Random Variables: Variables whose values depend on random outcomes. For example, could represent the pixel values in an image, which vary randomly based on the image content.
Distributions: Functions that describe the likelihood of different outcomes:
- Bernoulli distribution: (binary outcomes)
- Gaussian (Normal) distribution: (bell curve)
Key concepts:
- Expected value: (the average value)
- Variance: (spread of the distribution)
- Independence: Two events are independent if
Why it matters: Many neural network outputs are probabilistic (e.g., classification probabilities). We also use probability to measure uncertainty, regularize models, and generate diverse outputs.
Derivatives and Gradients
To train neural networks, we need to optimize functions. Derivatives tell us how functions change.
Derivative: The rate of change of a function at a point:
For a function , the derivative is . This tells us that at , the function is increasing at a rate of 6.
Gradient: The generalization of derivatives to multivariable functions. For , the gradient is:
The gradient points in the direction of steepest ascent—this is crucial for optimization.
Example: For , . At point , the gradient is , pointing in the direction of fastest increase.
Chain Rule: When functions are composed, we can compute derivatives using:
This rule is the mathematical backbone of backpropagation, which we’ll cover in Phase 3.
Why it matters: Neural networks learn by adjusting parameters to minimize a loss function. The gradient tells us which direction to adjust each parameter to reduce the loss.
Connecting the Dots
These three pillars—linear algebra, probability, and calculus—work together in neural networks:
- Linear algebra provides the structure for representing and transforming data
- Probability models uncertainty and guides learning objectives
- Calculus (gradients) enables us to optimize the network
In the next phase, we’ll see how these concepts combine in gradient descent and loss functions, setting the stage for understanding how neural networks actually learn.
Phase 2:
In Phase 1, we built the mathematical toolkit: linear algebra for data transformation, probability for modeling uncertainty, and calculus for understanding change. Now we’ll see how these tools combine to create the learning mechanism at the heart of all neural networks.
Loss Functions: Measuring Error
To learn, a neural network needs to know how well it’s doing. A loss function (or cost function) quantifies the error between predictions and true values.
Common Loss Functions
Mean Squared Error (MSE): For regression problems
Where is the true value and is the predicted value. The difference is squared to penalize large errors more heavily.
Cross-Entropy Loss: For classification problems
Where is the number of classes, is the true label (one-hot encoded), and is the predicted probability. This loss heavily penalizes confident wrong predictions.
Example: If we’re classifying images as “cat”, “dog”, or “bird”, and the true label is “cat” (), a prediction of would have low loss, while would have high loss.
Why it matters: The loss function is our objective. Everything in training is about minimizing this function. A good loss function accurately reflects what we care about in the real world.
Gradient Descent: The Learning Algorithm
Once we have a loss function, how do we minimize it? The answer is gradient descent.
Intuition
Imagine you’re on a mountain in thick fog. You want to reach the lowest point (the valley), but you can’t see the terrain. What do you do?
- Feel the ground around you to determine which direction slopes downward
- Take a step in that direction
- Repeat until you reach the bottom
This is gradient descent: the loss landscape is our mountain, the gradient points downhill, and each step is a parameter update.
The Algorithm
For a parameter vector (all weights and biases in the network):
- Compute gradient:
- Update parameters:
- Repeat until convergence
The learning rate (eta) controls step size:
- Too small: Learning is very slow
- Too large: We might overshoot or diverge
Example: One-Dimensional Case
Let . We want to find that minimizes this.
The gradient is:
Starting at with learning rate :
- Step 1: Gradient , update:
- Step 2: Gradient , update:
- Step 3: Gradient , update:
We’re moving toward , the true minimum!
Stochastic Gradient Descent (SGD)
In practice, we use stochastic gradient descent: instead of computing the gradient over all training data, we use a small batch (mini-batch).
Where is a random batch of training examples.
Why SGD?
- Computationally efficient (don’t need all data for each update)
- Noisy updates help escape local minima
- Works better with large datasets
Advanced Optimizers
Modern training rarely uses vanilla SGD. Popular variants include:
- Momentum: Accumulates past gradients to accelerate through flat regions
- Adam: Combines momentum with adaptive learning rates
- RMSprop: Adapts learning rates per parameter
These build on the same gradient descent principle but use the gradient more intelligently.
The Importance of Gradients in Network Training
Gradients are the lifeblood of neural network training. Let’s understand why.
Gradients Guide Learning
Each gradient component tells us:
- How much the loss would change if we increased by a tiny amount
- Which direction to move to reduce loss
A large positive gradient means “decrease this parameter to reduce loss,” while a large negative gradient means “increase this parameter to reduce loss.”
Vanishing and Exploding Gradients
Two common problems in deep networks:
Vanishing gradients: In very deep networks, gradients can become extremely small, making early layers learn very slowly. This was a major challenge in early neural networks.
Exploding gradients: Gradients can become extremely large, causing parameters to change drastically and training to become unstable.
Solutions include:
- Careful initialization (e.g., Xavier, He initialization)
- Activation functions with well-behaved gradients (we’ll see these in Phase 3)
- Gradient clipping
- Residual connections (skip connections)
Gradient Flow Through the Network
In a deep network, gradients flow backward from the output to the input:
Input → [Layer 1] → [Layer 2] → ... → [Output] ↑ ↑ ↑ Gradient Gradient Gradient (starts here)If gradients vanish early, the early layers (which often learn fundamental features) don’t get useful training signals. If gradients explode, training becomes unstable.
Why it matters: Understanding gradient flow helps us design better architectures. Modern breakthroughs like residual networks were motivated specifically to improve gradient flow.
Putting It All Together
We now have a complete picture of the learning loop:
- Forward pass: Compute predictions using current parameters
- Compute loss: Measure error using a loss function
- Backward pass: Compute gradients of the loss with respect to all parameters
- Update parameters: Move parameters in the opposite direction of gradients
- Repeat
This loop, applied thousands or millions of times, is how neural networks learn from data. In Phase 3, we’ll dive into the neural network architecture itself—how neurons, layers, and activation functions work together to create powerful function approximators.
Phase 3:
In Phases 1 and 2, we covered the mathematical machinery: linear algebra for transformations, probability for modeling, and gradient descent for optimization. Now we’ll see how these pieces assemble into neural networks—the function approximators that can learn complex patterns from data.
What is a Neural Network?
At its core, a neural network is a mathematical function composed of simpler functions. It takes inputs, applies a series of transformations, and produces outputs. The “magic” is that the transformations are parameterized, and we learn those parameters from data.
Mathematically: A neural network computes where is the input and represents all learnable parameters.
Conceptually: It’s a computational graph where nodes perform operations and edges represent data flow.
The Perceptron: The Building Block
The perceptron is the simplest neural network unit—a single artificial neuron.
Structure
A perceptron takes inputs and produces one output:
Inputs: x₁, x₂, ..., xₙ ↓ ↓ ↓Weights: w₁, w₂, ..., wₙ ↓ ↓ ↓ Sum: z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b ↓ Activation: a = σ(z) ↓ Output: y = aMathematically:
Where:
- is the weight vector
- is the bias (allows shifting the activation function)
- is an activation function
- is called the “pre-activation”
Geometric Intuition
The computation is a hyperplane in . The perceptron decides which side of this hyperplane the input falls on.
For 2D inputs :
- The decision boundary is the line
- Points above the line have , below have
Limitations of Single Perceptrons
A single perceptron can only learn linearly separable functions. It cannot solve the XOR problem, which requires a non-linear decision boundary.
Solution: Stack multiple perceptrons to create a multi-layer perceptron (MLP).
Feed-Forward Networks
A feed-forward network (or multi-layer perceptron) consists of layers of perceptrons connected sequentially.
Architecture
Input Layer Hidden Layer 1 Hidden Layer 2 Output Layer [x₁] ──────► [h₁₁] ──────► [h₂₁] ──────► [y₁] [x₂] ──────► [h₁₂] ──────► [h₂₂] ──────► [y₂] [x₃] ──────► [h₁₃] ──────► [h₂₃] ──────► [y₃] ... ...Each layer transforms the representation:
Where (input) and (output).
Why multiple layers?: Each layer learns increasingly abstract features. In image recognition, early layers might detect edges, middle layers detect shapes, and later layers detect objects.
Universal Approximation Theorem
A remarkable theoretical result: A feed-forward network with a single hidden layer and non-linear activation can approximate any continuous function to arbitrary accuracy (given enough neurons).
This means neural networks are incredibly flexible function approximators—they can learn virtually any mapping from inputs to outputs given sufficient capacity.
Activation Functions: Adding Non-Linearity
Without activation functions, a multi-layer network would just be a series of linear transformations, which could be collapsed into a single linear transformation. Activation functions introduce non-linearity, enabling the network to learn complex, non-linear patterns.
Sigmoid
Properties:
- Output in (interpretable as probability)
- Smooth gradient:
- Historically popular but suffers from vanishing gradients
Use case: Binary classification output
ReLU (Rectified Linear Unit)
Properties:
- Simple: if , else
- Sparse activation (many neurons output zero)
- Avoids vanishing gradient (gradient is 1 for positive inputs)
- Computationally efficient
Use case: Hidden layers in most modern networks
Why ReLU Won
ReLU’s simplicity and lack of vanishing gradient problems made it the default choice for hidden layers. Variants like Leaky ReLU and ELU address the “dying ReLU” problem (neurons that never activate).
The Forward Pass: Making Predictions
The forward pass computes the network’s output given inputs.
Step-by-step:
- Input enters the first layer
- For each layer to : a. Compute pre-activation: b. Apply activation:
- Output is the prediction
Example: For a network with one hidden layer:
# Forward passz_hidden = W_hidden @ x + b_hiddenh_hidden = relu(z_hidden)z_output = W_output @ h_hidden + b_outputy_pred = sigmoid(z_output) # For binary classificationBackpropagation: Learning from Mistakes
Backpropagation is the algorithm that computes gradients efficiently for neural networks. It applies the chain rule recursively from the output to the input.
The Chain Rule in Action
For a simple network with one hidden layer:
To find , we chain through the computation:
Simplified Backprop Algorithm
- Forward pass: Store all intermediate values (, )
- Output gradient: Compute
- Backward pass: For each layer to :
- Parameter gradients:
Computational Efficiency
The key insight of backpropagation is that we compute gradients in time where is the number of parameters, rather than for naive numerical differentiation. This makes training large networks feasible.
Example: Computing a Gradient
For a single neuron with input , weight , bias , sigmoid activation, and MSE loss:
- Forward: , ,
- Backward:
This tells us exactly how to adjust to reduce the loss.
Putting It Together: Training Loop
We now have all the pieces:
# Initialize parametersW_hidden, b_hidden = initialize_weights()W_output, b_output = initialize_weights()
for epoch in range(num_epochs): for batch in data_loader: # Forward pass z_hidden = W_hidden @ x + b_hidden h_hidden = relu(z_hidden) z_output = W_output @ h_hidden + b_output y_pred = sigmoid(z_output)
# Compute loss loss = binary_cross_entropy(y, y_pred)
# Backward pass (backprop) grad_output = (y_pred - y) * y_pred * (1 - y_pred) grad_W_output = grad_output @ h_hidden.T grad_b_output = grad_output
grad_hidden = (W_output.T @ grad_output) * (z_hidden > 0) grad_W_hidden = grad_hidden @ x.T grad_b_hidden = grad_hidden
# Update parameters (gradient descent) W_output -= learning_rate * grad_W_output b_output -= learning_rate * grad_b_output W_hidden -= learning_rate * grad_W_hidden b_hidden -= learning_rate * grad_b_hiddenIn Phase 4, we’ll explore how these basic networks evolved into the sophisticated architectures powering modern AI, including attention mechanisms and transformers.
Phase 4:
We’ve covered the foundations: linear algebra, probability, calculus, gradient descent, and basic neural networks. Now we arrive at the architectures that have revolutionized AI—attention mechanisms and transformers. These concepts, combined with embeddings, power models like GPT, BERT, and the current generation of AI systems.
Embeddings: Representing Meaning as Vectors
Before understanding attention, we need to understand how we represent discrete inputs (like words) as continuous vectors that neural networks can process.
From One-Hot to Dense Vectors
One-hot encoding: Represent each word as a sparse vector where only one position is 1.
"cat" = [1, 0, 0, 0, ...]"dog" = [0, 1, 0, 0, ...]"bird" = [0, 0, 1, 0, ...]Problems: High dimensionality, no notion of similarity, no relationship between words.
Word embeddings: Learn dense, low-dimensional vectors where semantic similarity corresponds to geometric similarity.
"cat" ≈ [0.2, -0.5, 0.8, 0.1, ...]"dog" ≈ [0.3, -0.4, 0.7, 0.2, ...]"bird" ≈ [0.9, 0.3, -0.2, 0.5, ...]Now “cat” and “dog” have similar vectors (they’re semantically related), while “bird” is different.
Why Embeddings Work
Words that appear in similar contexts should have similar meanings. By learning to predict words from context (or vice versa), we automatically capture semantic relationships.
Famous property: Vector arithmetic captures relationships:
king - man + woman ≈ queenThe direction from “man” to “woman” is similar to the direction from “king” to “queen”!
Training Embeddings
Word2Vec: Two approaches:
- Skip-gram: Predict context words from target word
- CBOW: Predict target word from context
GloVe: Factorize word co-occurrence matrix
Modern approach: Learn embeddings as part of the model training rather than pre-training separately.
Beyond Words
Embeddings extend beyond words:
- Character embeddings: For subword information
- Positional embeddings: For sequence order
- Sentence embeddings: For entire documents
- Multimodal embeddings: For images, audio, etc.
Attention: What It Is and Why It Matters
Attention mechanisms allow models to focus on relevant parts of the input when producing each part of the output. This was a breakthrough that solved limitations of sequence-to-sequence models.
The Problem with Fixed Representations
Before attention, sequence models (like RNNs) compressed an entire input sequence into a single fixed-size vector:
Input: "The cat sat on the mat"↓ (encode entire sentence)Fixed vector: [0.1, -0.3, 0.7, ...]↓ (decode)Output: "El gato se sentó en la alfombra"Problem: All information must be compressed into one vector, which becomes a bottleneck for long sequences.
The Attention Solution
Instead of using a fixed vector, let each output step look at different parts of the input, weighted by relevance.
When generating "El" → Focus on "The"When generating "gato" → Focus on "cat"When generating "se" → Focus on "sat"Mathematically, for output position , we compute a weighted sum of input representations:
Where is the attention weight from output position to input position .
Computing Attention Weights
How do we compute ? We use a compatibility function that measures how well input position relates to output position .
Dot-product attention:
Where:
- is the query vector (what we’re looking for)
- is the key vector (what the input offers)
- is the value vector (the actual content)
The softmax ensures weights sum to 1 (probability distribution).
Query, Key, Value (Q, K, V) Explained
The Q, K, V framework is the core of modern attention mechanisms. Let’s break it down with an intuitive example.
Intuition: Database Analogy
Think of it like a database query:
- Query (Q): What you’re searching for
- Key (K): How items are indexed
- Value (V): The actual content
Database: Key: "name", Value: "Alice" Key: "age", Value: 30 Key: "city", Value: "NYC"
Query: "name"→ Match: Key "name" matches Query "name"→ Return: Value "Alice"In Neural Networks
Each input position has its own K and V. Each output position has its own Q. We compute similarity between Q and all K’s, then weight V’s by these similarities.
Q, K, V in Code
def scaled_dot_product_attention(Q, K, V): """ Args: Q: (batch_size, seq_len, d_k) K: (batch_size, seq_len, d_k) V: (batch_size, seq_len, d_v) Returns: output: (batch_size, seq_len, d_v) attention_weights: (batch_size, seq_len, seq_len) """ # Compute similarity scores scores = Q @ K.transpose(-2, -1) # (batch_size, seq_len, seq_len)
# Scale to prevent extremely large softmax values scores = scores / np.sqrt(K.shape[-1])
# Apply softmax to get attention weights attention_weights = softmax(scores, axis=-1)
# Weight values by attention weights output = attention_weights @ V
return output, attention_weightsKey steps:
- Compute Q·K to get similarity scores
- Scale by (stabilizes gradients)
- Apply softmax to get probability distribution
- Weight sum of V’s
Multi-Head Attention
Instead of one set of Q, K, V, we use multiple “heads” that learn different relationships:
class MultiHeadAttention: def __init__(self, d_model, num_heads): self.d_model = d_model self.num_heads = num_heads self.d_k = d_model // num_heads
# Learnable projection matrices self.W_Q = initialize_weights((d_model, d_model)) self.W_K = initialize_weights((d_model, d_model)) self.W_V = initialize_weights((d_model, d_model)) self.W_O = initialize_weights((d_model, d_model))
def forward(self, x): batch_size, seq_len, _ = x.shape
# Project to Q, K, V for each head Q = x @ self.W_Q # (batch, seq_len, d_model) K = x @ self.W_K V = x @ self.W_V
# Split into heads and reshape Q = Q.reshape(batch_size, seq_len, self.num_heads, self.d_k) K = K.reshape(batch_size, seq_len, self.num_heads, self.d_k) V = V.reshape(batch_size, seq_len, self.num_heads, self.d_k)
# Transpose to (batch, num_heads, seq_len, d_k) Q = Q.transpose(1, 2) K = K.transpose(1, 2) V = V.transpose(1, 2)
# Compute attention for each head scores = Q @ K.transpose(-2, -1) / np.sqrt(self.d_k) attention_weights = softmax(scores, axis=-1) attended = attention_weights @ V
# Concatenate heads and project attended = attended.transpose(1, 2).reshape(batch_size, seq_len, self.d_model) output = attended @ self.W_O
return output, attention_weightsEach head can focus on different types of relationships:
- Head 1 might focus on syntactic structure
- Head 2 might focus on semantic similarity
- Head 3 might focus on positional relationships
Transformers: The Attention-Only Architecture
Transformers replace recurrence (RNNs) and convolution (CNNs) entirely with attention mechanisms.
Key Innovations
1. Self-attention: Instead of attention between encoder and decoder, each position attends to all other positions in the same sequence.
For each word "cat", compute attention weights with all words:"cat" attends to: "The"(0.1), "cat"(0.6), "sat"(0.2), "on"(0.05), "the"(0.03), "mat"(0.02)2. Positional encoding: Since attention doesn’t inherently capture order, we add position information:
These sinusoidal encodings allow the model to learn relative positions.
3. Parallelization: Unlike RNNs which process sequentially, transformers process all positions simultaneously, enabling massive parallelization on GPUs.
Transformer Architecture
Input Embedding + Positional Encoding ↓ ┌─────────────────┐ │ Encoder Stack │ │ (N times) │ │ │ │ ┌───────────┐ │ │ │ Multi-Head│ │ │ │ Attention │ │ │ └───────────┘ │ │ ↓ │ │ ┌───────────┐ │ │ │ Feed- │ │ │ │ Forward │ │ │ └───────────┘ │ └─────────────────┘ ↓ ┌─────────────────┐ │ Decoder Stack │ │ (N times) │ │ │ │ ┌───────────┐ │ │ │ Masked │ │ │ │ Multi-Head│ │ │ │ Attention │ │ │ └───────────┘ │ │ ↓ │ │ ┌───────────┐ │ │ │ Cross │ │ │ │ Attention│ │ │ └───────────┘ │ │ ↓ │ │ ┌───────────┐ │ │ │ Feed- │ │ │ │ Forward │ │ │ └───────────┘ │ └─────────────────┘ ↓ OutputEncoder: Processes input sequence and produces contextual representations
Decoder: Generates output sequence, attending to both encoder output and previously generated tokens
Masked attention: Prevents decoder from “seeing the future” during training (autoregressive)
Why Transformers Work So Well
- Long-range dependencies: Attention connects any two positions directly, no matter how far apart
- Parallelization: Process entire sequences at once, enabling training on massive datasets
- Interpretability: Attention weights show what the model focuses on
- Scalability: Performance continues to improve with more data and compute
From Transformers to LLMs
Modern large language models are essentially:
- Decoder-only transformers (for autoregressive text generation)
- Trained on massive text datasets
- Scaled up with more parameters, more data, and more compute
The architecture we’ve discussed is essentially the same as GPT, BERT, and LLaMA—just scaled up.
The Complete Picture
We’ve now traced the complete journey:
- Linear algebra: Vectors and matrices represent and transform data
- Probability: Models uncertainty and defines learning objectives
- Calculus: Gradients guide parameter updates
- Gradient descent: The optimization algorithm that learns parameters
- Neural networks: Parameterized function approximators composed of layers
- Perceptrons: Building blocks with weights, biases, and activations
- Forward/backprop: Making predictions and computing gradients
- Activations: ReLU and sigmoid introduce non-linearity
- Embeddings: Discrete symbols become meaningful continuous vectors
- Attention: Models dynamically focus on relevant information
- Q/K/V: Framework for computing relevance and importance
- Transformers: Attention-based architectures that process sequences
- Modern AI: Scale these principles to achieve remarkable capabilities
Each concept builds on the previous ones, creating a mathematical foundation that enables machines to learn from data and perform increasingly sophisticated tasks. Understanding these foundations demystifies AI and provides the intuition to innovate and build the next generation of intelligent systems.
Conclusion
We’ve traced the complete journey from basic mathematical operations to cutting-edge AI architectures. Each concept builds on the previous ones, creating a coherent framework for understanding how machines learn:
- Linear algebra provides the language for representing and transforming data
- Probability helps us model uncertainty and define what we want to learn
- Calculus (gradients) shows us how to improve our models
- Gradient descent is the algorithm that drives learning
- Neural networks are the flexible function approximators that learn from data
- Attention mechanisms allow models to focus on what matters
- Transformers leverage attention to process sequences efficiently
This knowledge isn’t just academic—it’s the foundation for building, understanding, and improving AI systems. Whether you’re implementing a neural network, debugging a transformer model, or designing a new architecture, these fundamentals provide the intuition and tools you need.
The next time you use ChatGPT, generate images with DALL-E, or interact with any AI system, you’ll understand the mathematical machinery working beneath the surface. And perhaps more importantly, you’ll be equipped to contribute to the next generation of AI innovations.