TL;DR
- The boundary pattern — sanitize before, filter after — leaks. Agents fail mid-loop: the model picks a weird tool, hallucinates a refund, or burns $40 in retries.
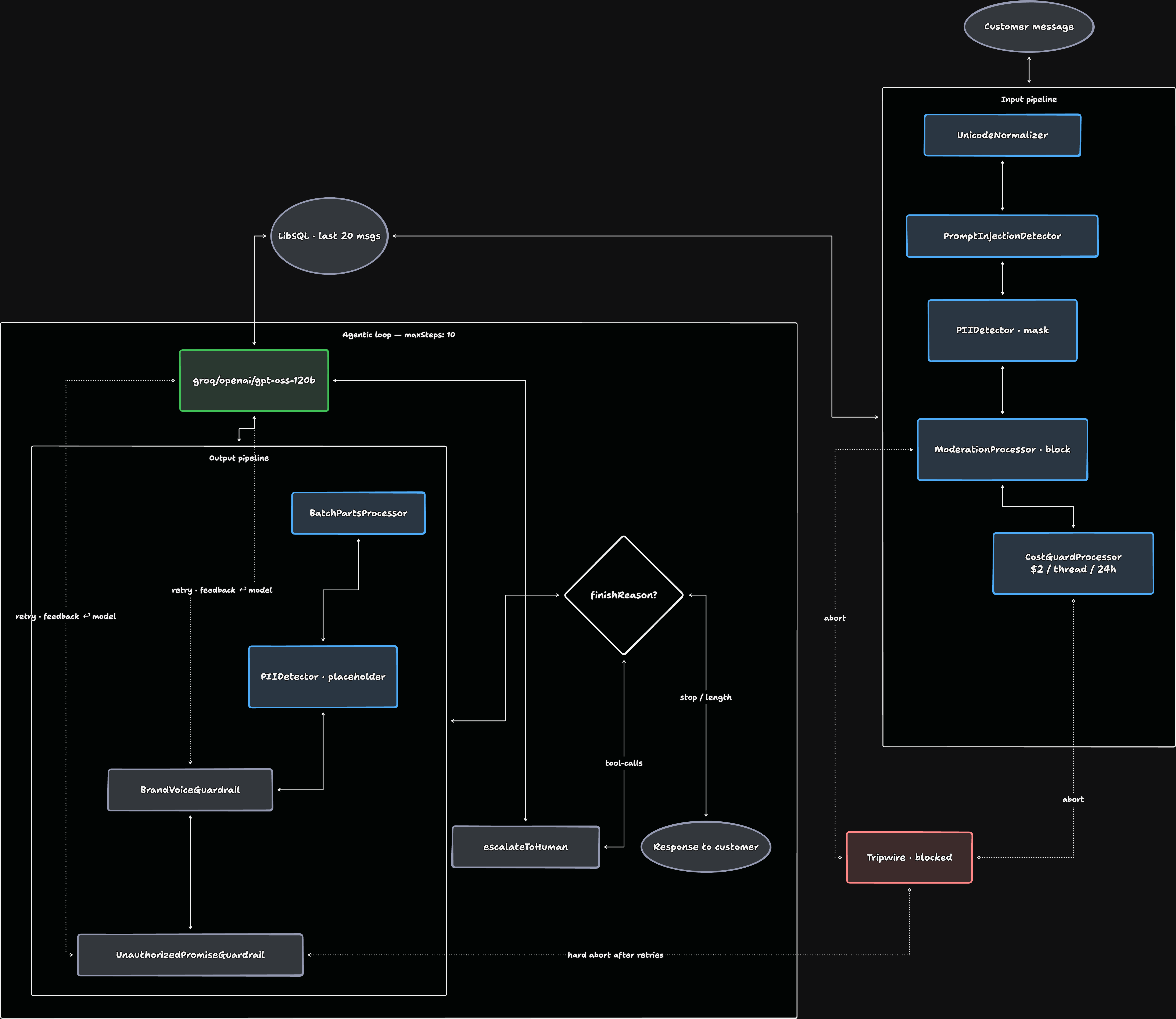
- Mastra splits guardrails into
inputProcessors(before the LLM) andoutputProcessors(after), both running on every step. - The retry loop —
abort({ retry: true })+retryCount+maxProcessorRetries— turns a guardrail from “block” into “tell the model what it did wrong and try again.” - A real customer-facing stack is five input processors and four output processors. I’ll walk through the one I ship.
- Part 2 of a series on harness engineering with Mastra. Part 1 covers the harness map.
Why the boundary pattern isn’t enough
The default guardrail design from tutorials:
- Validate user input before it reaches the agent.
- Filter the agent’s final output before it reaches the user.
That’s the boundary pattern. Right starting point, nowhere near sufficient for anything customer-facing.
An agent’s loop isn’t one input → output. It’s reason → tool call → observe → reason → … → final response. Each reasoning step can fail: the model picks the wrong tool, produces a vague intermediate response that poisons the next step, loops on the same call, or commits to something it has no authority to commit to.
None of those look bad at the boundary. They produce a bad final answer, a high bill, an angry customer, or all three.
Mastra processors run inside the loop — on every step, on every model output, before and after every tool call.
The two pipelines
Mastra agents have three processor arrays:
new Agent({ inputProcessors: [...], // before the LLM, every step outputProcessors: [...], // after the LLM, every step errorProcessors: [...], // when the provider API rejects the call});Input processors don’t just run on the first user message — they run on each step, including the ones that come back from tool calls. Output processors run on every model response before tools fire and before memory persists anything.
That last detail matters. If an output processor aborts, memory doesn’t save the bad response. The agent’s history stays clean.
The input pipeline
Cheap, fast, defensive stuff — things that run before you spend any money on the main model.
import { CostGuardProcessor, ModerationProcessor, PIIDetector, PromptInjectionDetector, UnicodeNormalizer,} from '@mastra/core/processors';
const GUARDRAIL_MODEL = 'groq/openai/gpt-oss-120b';
export const supportAgent = new Agent({ // ... inputProcessors: [ new UnicodeNormalizer({ stripControlChars: true, collapseWhitespace: true, trim: true, }), new PromptInjectionDetector({ model: GUARDRAIL_MODEL, strategy: 'rewrite', threshold: 0.8, detectionTypes: ['injection', 'jailbreak', 'system-override'], lastMessageOnly: true, }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'mask', threshold: 0.6, detectionTypes: ['email', 'phone', 'credit-card', 'ssn'], preserveFormat: true, lastMessageOnly: true, }), new ModerationProcessor({ model: GUARDRAIL_MODEL, strategy: 'block', threshold: 0.7, categories: ['hate', 'harassment', 'violence', 'sexual'], lastMessageOnly: true, }), new CostGuardProcessor({ maxCost: 2.0, scope: 'thread', window: '24h', }), ],});Order is deliberate.
UnicodeNormalizer runs first. Strips zero-width spaces, normalizes weird Unicode, collapses whitespace. Cheap, deterministic, and catches a surprising amount of low-effort injection (invisible characters from copy-pasted prompts).
PromptInjectionDetector runs second. A classifier scores the message against jailbreak patterns. I use 'rewrite' instead of 'block' because legitimate users sometimes look like injectors by accident (“ignore the previous question, what about…”). Rewriting neutralizes the pattern; the conversation continues.
PIIDetector runs third. Emails, phones, and cards are masked before the main model sees them — both for compliance and to keep your prompts from being a PII surface in your provider’s logs. lastMessageOnly: true is critical or the detector rescans full history every step.
ModerationProcessor runs fourth. Same shape, different categories. I block on this one — no point rewriting hate speech into a question.
CostGuardProcessor runs last. By here the message is normalized, neutralized, redacted, and moderated. The cost guard aborts before the main model call if the thread has hit its cap. scope: 'thread' + window: '24h' = “200 ranting at the agent.
The pattern: cheap and deterministic first, expensive and probabilistic last. UnicodeNormalizer doesn’t even hit the network. The main agent call only happens if everything before it agreed it should.
The output pipeline and the retry loop
Output processors enforce taste — voice, accuracy, business rules. They run on every model response before tools fire, so they can demand a retry and the conversation history never sees the bad version.
import { BatchPartsProcessor, PIIDetector,} from '@mastra/core/processors';import { BrandVoiceGuardrail } from '../processors/brand-voice-guardrail';import { UnauthorizedPromiseGuardrail } from '../processors/unauthorized-promise-guardrail';
outputProcessors: [ new BatchPartsProcessor({ batchSize: 10, maxWaitTime: 150 }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'placeholder', threshold: 0.6, detectionTypes: ['email', 'phone', 'credit-card', 'ssn'], }), new BrandVoiceGuardrail(), new UnauthorizedPromiseGuardrail(),],maxProcessorRetries: 3,BatchPartsProcessor is a streaming perf trick I’ll come back to.
PII runs on output too — the model can leak data it picked up earlier in the conversation (a customer’s email, an order ID that wasn’t theirs). Same class, different config (placeholder reads better in customer replies than mask).
The two custom guardrails are where the interesting work happens.
Custom guardrail #1: brand voice
Two failure modes show up constantly in customer-facing agents:
- Vague refusals. “I cannot help with that” when there’s a knowledge base search sitting right there.
- AI-voice. “As an AI assistant, I…” — the moment a customer reads that, trust drops.
The processor I ship:
import type { Processor } from '@mastra/core/processors';
const MIN_USEFUL_CHARS = 80;
const VOICE_VIOLATIONS = [ { pattern: /\bas an (ai|llm|language model|assistant)\b/i, feedback: 'Drop the "As an AI..." framing. Speak as a member of the support team — direct and helpful.', }, { pattern: /^i (don't|do not|can't|cannot) (know|find|access|browse|see)/i, feedback: 'Avoid vague refusals. Search the knowledge base, look up the account, or escalate before saying you cannot help.', }, { pattern: /\b(unfortunately|sadly),? i('m| am) (unable|not able)/i, feedback: 'No theatrical apologies. State the constraint, then offer the next step the customer can take.', },];
export class BrandVoiceGuardrail implements Processor { id = 'brand-voice-guardrail';
async processOutputStep({ text, abort, retryCount, finishReason, messageList, }: Parameters<NonNullable<Processor['processOutputStep']>>[0]) { if (finishReason === 'tool-calls' || !text) return messageList;
const issues: string[] = [];
if (text.length < MIN_USEFUL_CHARS) { issues.push( 'Response is too short to be useful to the customer — expand with concrete steps.', ); }
for (const { pattern, feedback } of VOICE_VIOLATIONS) { if (pattern.test(text)) issues.push(feedback); }
if (issues.length > 0 && retryCount < 3) { abort(issues.join(' '), { retry: true, metadata: { processor: this.id, issues }, }); }
return messageList; }}Four decisions worth pulling out.
The early return is load-bearing. Steps that only produced a tool call don’t have text. Run text checks on them anyway and you get false positives that retry forever.
abort is more than “stop.” Called with { retry: true }, the step restarts and the reason string is fed back into the model’s context as a correction. Treat those strings like prompts — because they are.
The retry budget is bounded twice. Once in the processor (retryCount < 3) and once on the agent (maxProcessorRetries: 3). I gate inside the processor too because relying only on the agent cap turns a failing guardrail into a silent step-eater inside a longer loop.
Patterns are regex, not LLM judges. Output processors run on every step. A slow guardrail compounds. Save semantic checks for scorers that run async after the run completes.
Custom guardrail #2: unauthorized promises
Brand voice is taste. This one is a hard business rule.
Customer support agents talk about money — refunds, credits, SLA terms. None of those decisions belong to the LLM. They belong to a human with authority. The model’s job is to triage and escalate.
import type { Processor } from '@mastra/core/processors';
const COMMITMENT_PATTERNS = [ /\b(refund|credit|reimburse|chargeback)\b/i, /\b(guarantee[ds]?|promise|commit) (?:that|to|you)\b/i, /\b(100%|always|never) (?:uptime|available|working)\b/i, /\bwe will (?:waive|comp|discount|cancel)\b/i, /\b(SLA|service level agreement)\b/i,];
export class UnauthorizedPromiseGuardrail implements Processor { id = 'unauthorized-promise-guardrail';
async processOutputStep({ text, abort, retryCount, finishReason, messageList, }: Parameters<NonNullable<Processor['processOutputStep']>>[0]) { if (finishReason === 'tool-calls' || !text) return messageList;
const triggered = COMMITMENT_PATTERNS.filter((p) => p.test(text)); if (triggered.length === 0) return messageList;
if (retryCount < 2) { abort( 'You made a commitment the support agent is not authorized to make ' + '(refund, credit, guarantee, or SLA promise). Do not commit on the company\'s behalf — ' + 'call the escalateToHuman tool with a precise summary so a human agent can approve.', { retry: true, metadata: { processor: this.id, patterns: triggered.map(String) }, }, ); }
abort( 'This request needs approval from a human support agent. It has been flagged for escalation.', { metadata: { processor: this.id, patterns: triggered.map(String) } }, ); return messageList; }}Notice: the retry message doesn’t just say “don’t do that.” It tells the model what to do instead — call escalateToHuman. That tool sits in the agent’s toolbelt:
export const escalateToHuman = createTool({ id: 'escalate-to-human', description: 'Escalate the conversation to a human support agent. Use when the customer ' + 'requests a refund, account changes, contract renegotiation, or any commitment ' + 'beyond providing information from the knowledge base.', inputSchema: z.object({ reason: z.string().min(10), urgency: z.enum(['low', 'normal', 'high']), summary: z.string(), }), // ...});The pattern: a processor catches the model doing the wrong thing and redirects it to the right tool. After one retry the model usually gets it. The customer ends up with a ticket ID (“flagged for our team, ticket T-XYZ, ~12 min response”) instead of a generic refusal.
If the model still won’t escalate after two retries, the processor hard-aborts with a safe public message. That third path matters — without it, a buggy model could burn the whole retry budget on the same mistake.
Performance: batching and parallelism
A stack of five guardrails can double the latency of every step. How to keep them fast:
Trick 1: lastMessageOnly: true. Without it, every guardrail rescans full history on every step. With it, only the latest message. On long conversations the difference is 10x in classifier calls.
Trick 2: smaller classifier models for guardrails. The main agent might be a 120B model; the guardrail classifiers don’t have to be. A purpose-built smaller classifier (Llama Prompt-Guard, gpt-oss-safeguard) does the same job ~5x faster and cheaper. I run everything on the main model in this example for simplicity — swap in a smaller one before going to scale.
Trick 3: BatchPartsProcessor. Streaming agents emit dozens of text-delta chunks per second. Running an LLM-backed guardrail on each one is suicide. BatchPartsProcessor collects chunks and emits them in groups:
outputProcessors: [ new BatchPartsProcessor({ batchSize: 10, maxWaitTime: 150 }), // every guardrail below sees batches of ~10 chunks new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact' }),],Always put it before any expensive output processor.
Trick 4: parallel workflow processors. Multiple guardrails that only block (no mutation) are independent and can run together. Wrap them in a workflow with .parallel() and pass that as a single “processor”:
import { createWorkflow, createStep } from '@mastra/core/workflows';import { ProcessorStepSchema, PIIDetector, ModerationProcessor } from '@mastra/core/processors';
const outputGuardrails = createWorkflow({ id: 'output-guardrails', inputSchema: ProcessorStepSchema, outputSchema: ProcessorStepSchema,}) .parallel([ createStep(new PIIDetector({ strategy: 'redact' })), createStep(new ModerationProcessor({ strategy: 'block' })), ]) .map(async ({ inputData }) => inputData['processor:pii-detector']) .commit();The .map step picks which branch’s output to carry forward. If you have any mutating processors (redact), map to that branch.
Not worth reaching for until you have at least three independent LLM-backed guardrails. Below that the workflow overhead doesn’t pay off.
What processors are not for
Processors run synchronously inside the agent loop. Right tool for fast semantic checks, wrong tool for:
Expensive LLM-based evaluation. Judging citation quality with a large judge model belongs in a scorer (async, sampled, doesn’t block the loop). Putting an LLM call inside processOutputStep doubles latency and cost on every step.
Side effects. Don’t send notifications, update databases, or call external APIs inside a processor. If the step retries, the processor runs again and you fire the side effect twice. Side effects belong in tool execute functions or post-run hooks. Exception: onViolation callbacks, which are explicitly fire-and-forget for logging and paging.
Structural validation. Your tool input schemas already do this. Trust Mastra’s schema layer; don’t re-implement it.
The line: fast, semantic, about the model’s reasoning — it’s a processor. Slow, expensive, or a side effect — it isn’t.
The full production stack
For the customer support agent, end to end:
export const supportAgent = new Agent({ id: 'support-agent', name: 'Support Agent', instructions: `...`, model: 'groq/openai/gpt-oss-120b', tools: { escalateToHuman }, memory: new Memory({ storage: new LibSQLStore({ id: 'support-storage', url: 'file:./mastra.db' }), options: { lastMessages: 20 }, }), inputProcessors: [ new UnicodeNormalizer({ stripControlChars: true, collapseWhitespace: true, trim: true }), new PromptInjectionDetector({ model: GUARDRAIL_MODEL, strategy: 'rewrite', threshold: 0.8, lastMessageOnly: true }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'mask', lastMessageOnly: true }), new ModerationProcessor({ model: GUARDRAIL_MODEL, strategy: 'block', threshold: 0.7, lastMessageOnly: true }), new CostGuardProcessor({ maxCost: 2.0, scope: 'thread', window: '24h' }), ], outputProcessors: [ new BatchPartsProcessor({ batchSize: 10, maxWaitTime: 150 }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'placeholder' }), new BrandVoiceGuardrail(), new UnauthorizedPromiseGuardrail(), ], maxProcessorRetries: 3, defaultOptions: { maxSteps: 10 },});Five input processors, four output processors, a budget cap, a retry ceiling. ~30 lines of agent config and two custom processor files. Small enough to fit on one screen, complete enough to put in front of real customers.
The mental model: processors are the immune system of the harness. Small, fast checks running constantly, with the ability to say “no, try again” before anything bad propagates.
Frequently Asked Questions
What’s the difference between a processor and a scorer?
Processors run synchronously, inside the loop, every step. They can block, retry, or abort. Scorers run asynchronously, after the run completes, on a sample of runs. Processors gate the current run; scorers feed your long-term feedback loop. Complementary, not alternatives.
Can I use a processor to modify the response text, not just abort?
processOutputStep is observe-and-abort. But built-in processors with strategy: 'redact' or strategy: 'rewrite' do mutate messages — PIIDetector, PromptInjectionDetector, SystemPromptScrubber. Pattern: built-ins handle mutation, custom processors handle business rules and retries.
How does maxProcessorRetries interact with maxSteps?
Each retry counts as a step. If maxSteps is 10 and maxProcessorRetries is 3, a guardrail that retries three times before passing burns 4 steps for what should be 1. Size maxSteps with retries in mind.
What happens if abort is called but there are no retries left?
retryCount >= maxProcessorRetries + abort(message, { retry: true }) becomes a hard abort — the run terminates with your message as the failure reason. Handle the exhausted case explicitly (like UnauthorizedPromiseGuardrail does) instead of relying on this implicit behaviour. Easier to trace.
Do input processors run on every step or just the first message?
processInput runs once at the start. processInputStep runs on every step. Built-ins like PromptInjectionDetector and PIIDetector use processInput, so they only inspect the original user message. CostGuardProcessor uses processInputStep because budget checks need to fire before every model call. Read the source to know which is which.
How do I detect a blocked response on the client?
For agent.generate(), check result.tripwire and result.finishReason === 'other'. For agent.stream(), listen for chunk.type === 'tripwire' in fullStream. Both expose processorId and reason so you can branch the UI on what fired.
Closing
The boundary pattern is where everyone starts. Processors are what you add when you’ve watched your agent confidently promise a refund it can’t give, burn eight steps in a loop, or leak a customer’s email back to them — and you want those failure modes to never reach the user again.
Next episode: MCP tools and why the description string of a tool is the most important string in your harness.
If you’re building something here, find me on X.