TL;DR
- El patrón de frontera — sanear antes, filtrar después — tiene fugas. Los agents fallan en medio del loop: el modelo elige una tool rara, alucina un reembolso, o quema $40 en reintentos.
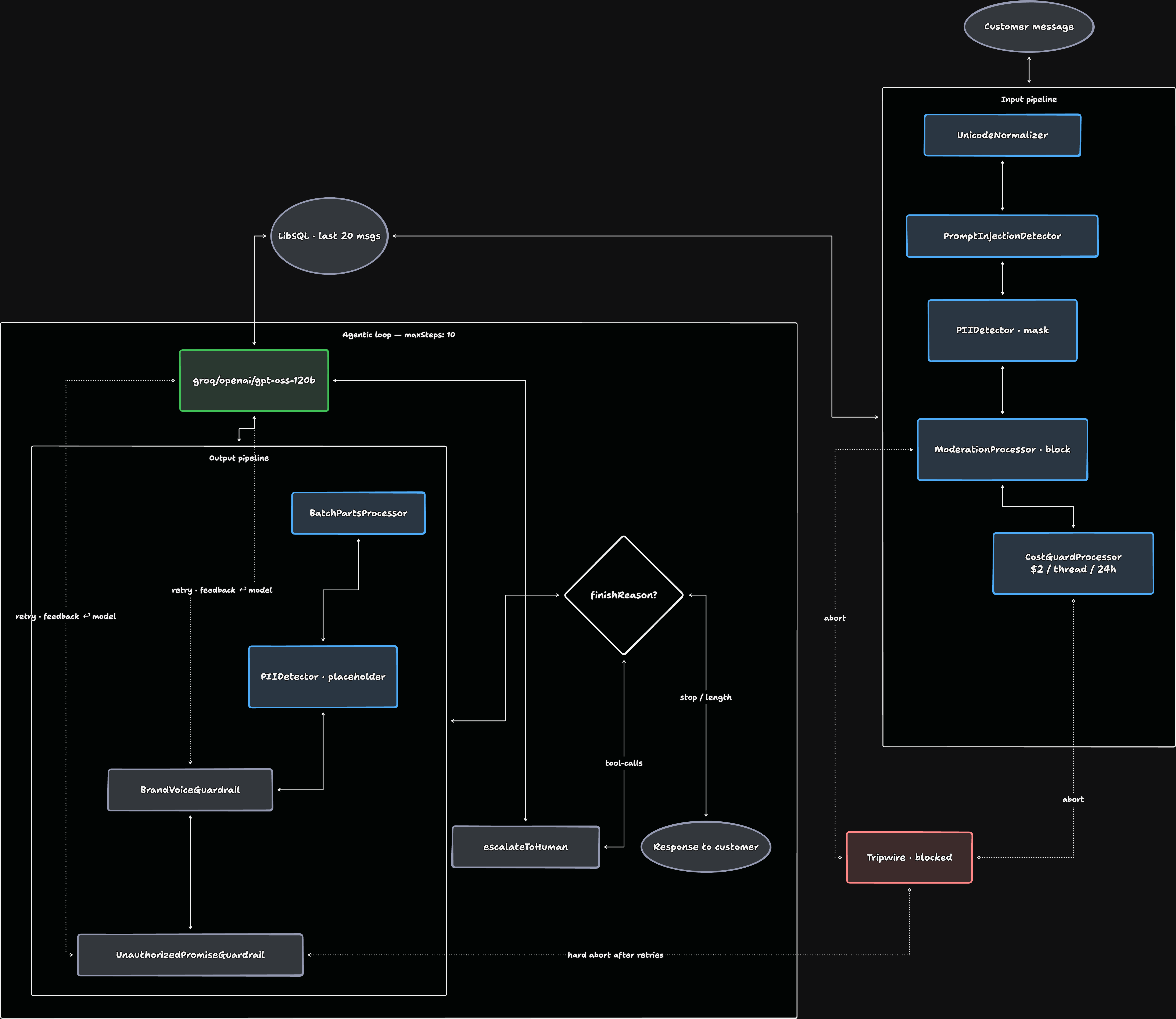
- Mastra divide los guardrails en
inputProcessors(antes del LLM) youtputProcessors(después), y ambos corren en cada paso. - El loop de reintentos —
abort({ retry: true })+retryCount+maxProcessorRetries— es lo que convierte un guardrail de “bloquear” a “decirle al modelo qué hizo mal y dejar que vuelva a intentar”. - Un stack real para un agent de cara al cliente tiene cinco processors de entrada y cuatro de salida. A continuación recorro el que yo despliego.
- Este es el segundo post de una serie sobre harness engineering con Mastra. La parte 1 cubre el mapa del harness.
Por qué el patrón de frontera no alcanza
El diseño de guardrails que aparece por defecto en los tutoriales:
- Validar el input del usuario antes de que llegue al agent.
- Filtrar la salida final del agent antes de mostrarla al usuario.
Ese es el patrón de frontera. Buen punto de partida, pero lejos de ser suficiente para algo de cara al cliente.
El loop de un agent no es un único input → output. Es razonar → llamar tool → observar → razonar → … → respuesta final. Cada paso de razonamiento puede fallar: el modelo elige la tool equivocada, produce una respuesta intermedia vaga que envenena al siguiente paso, queda en loop sobre la misma llamada, o se compromete a algo que no tiene autoridad para comprometer.
Ninguno de esos errores se ve mal en la frontera. Solo terminan en una respuesta final mala, una factura alta, un cliente enojado, o las tres cosas juntas.
Los processors de Mastra corren adentro del loop — en cada paso, sobre cada salida del modelo, antes y después de cada llamada a una tool.
Los dos pipelines
Los agents de Mastra tienen tres arrays de processors:
new Agent({ inputProcessors: [...], // antes del LLM, en cada paso outputProcessors: [...], // después del LLM, en cada paso errorProcessors: [...], // cuando el API del proveedor rechaza la llamada});Los input processors no solo corren sobre el primer mensaje del usuario — corren en cada paso, incluidos los que vienen de regreso desde llamadas a tools. Los output processors corren sobre cada respuesta del modelo antes de que se disparen las tools y antes de que la memoria persista nada.
Ese último detalle importa mucho. Si un output processor aborta, la memoria no guarda la respuesta mala. El historial del agent queda limpio.
El pipeline de entrada
Es donde van las cosas baratas, rápidas y defensivas — todo lo que conviene correr antes de gastar dinero en el modelo principal.
import { CostGuardProcessor, ModerationProcessor, PIIDetector, PromptInjectionDetector, UnicodeNormalizer,} from '@mastra/core/processors';
const GUARDRAIL_MODEL = 'groq/openai/gpt-oss-120b';
export const supportAgent = new Agent({ // ... inputProcessors: [ new UnicodeNormalizer({ stripControlChars: true, collapseWhitespace: true, trim: true, }), new PromptInjectionDetector({ model: GUARDRAIL_MODEL, strategy: 'rewrite', threshold: 0.8, detectionTypes: ['injection', 'jailbreak', 'system-override'], lastMessageOnly: true, }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'mask', threshold: 0.6, detectionTypes: ['email', 'phone', 'credit-card', 'ssn'], preserveFormat: true, lastMessageOnly: true, }), new ModerationProcessor({ model: GUARDRAIL_MODEL, strategy: 'block', threshold: 0.7, categories: ['hate', 'harassment', 'violence', 'sexual'], lastMessageOnly: true, }), new CostGuardProcessor({ maxCost: 2.0, scope: 'thread', window: '24h', }), ],});El orden es deliberado.
UnicodeNormalizer corre primero. Saca zero-width spaces, normaliza formas raras de Unicode y colapsa whitespace. Barato, determinista, y atrapa una cantidad sorprendente de intentos de injection de baja calidad (caracteres invisibles que vienen pegados de prompts copiados de blogs).
PromptInjectionDetector corre segundo. Un clasificador puntúa el mensaje contra patrones de jailbreak. Uso 'rewrite' en lugar de 'block' porque los usuarios legítimos a veces parecen atacantes sin querer (“ignorá la pregunta anterior, y respecto a…”). Reescribir neutraliza el patrón; la conversación sigue.
PIIDetector corre tercero. Emails, teléfonos y tarjetas quedan enmascarados antes de que el modelo principal los vea — tanto por cumplimiento como para que tus prompts no terminen siendo una superficie de PII en los logs del proveedor. lastMessageOnly: true es crítico, o el detector vuelve a escanear todo el historial en cada paso.
ModerationProcessor corre cuarto. Misma forma, distintas categorías. A este lo dejo en block — no tiene sentido reescribir discurso de odio como pregunta.
CostGuardProcessor corre al final. Para cuando llega acá, el mensaje ya está normalizado, neutralizado, redactado y moderado. El cost guard aborta antes de la llamada al modelo principal si el thread alcanzó su tope. scope: 'thread' + window: '24h' = “200 despotricando contra el agent una hora seguida.
El patrón: lo barato y determinista primero, lo caro y probabilístico al final. UnicodeNormalizer ni siquiera toca la red. La llamada al agent principal solo ocurre si todo lo anterior estuvo de acuerdo.
El pipeline de salida y el loop de reintentos
Los output processors imponen criterio — voz, exactitud, reglas de negocio. Corren sobre cada respuesta del modelo antes de que se disparen las tools, así que pueden pedir un reintento sin que el historial vea la versión mala.
import { BatchPartsProcessor, PIIDetector,} from '@mastra/core/processors';import { BrandVoiceGuardrail } from '../processors/brand-voice-guardrail';import { UnauthorizedPromiseGuardrail } from '../processors/unauthorized-promise-guardrail';
outputProcessors: [ new BatchPartsProcessor({ batchSize: 10, maxWaitTime: 150 }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'placeholder', threshold: 0.6, detectionTypes: ['email', 'phone', 'credit-card', 'ssn'], }), new BrandVoiceGuardrail(), new UnauthorizedPromiseGuardrail(),],maxProcessorRetries: 3,BatchPartsProcessor es un truco de performance para streaming, lo retomo más adelante.
PII también corre en la salida — el modelo puede filtrar datos que aprendió en turnos anteriores (el email de un cliente, un ID de orden que no era suyo). Misma clase, distinta config (placeholder lee mejor en respuestas a clientes que mask).
Los dos guardrails custom son donde está la parte interesante.
Guardrail custom #1: voz de marca
Hay dos modos de fallo que aparecen todo el tiempo en agents de cara al cliente:
- Rechazos vagos. “No puedo ayudarte con eso” cuando justo al lado tiene una búsqueda en la base de conocimiento.
- Voz de IA. “Como asistente de IA, yo…” — el momento en que un cliente lee eso, se cae la confianza.
El processor que yo uso:
import type { Processor } from '@mastra/core/processors';
const MIN_USEFUL_CHARS = 80;
const VOICE_VIOLATIONS = [ { pattern: /\bas an (ai|llm|language model|assistant)\b/i, feedback: 'Drop the "As an AI..." framing. Speak as a member of the support team — direct and helpful.', }, { pattern: /^i (don't|do not|can't|cannot) (know|find|access|browse|see)/i, feedback: 'Avoid vague refusals. Search the knowledge base, look up the account, or escalate before saying you cannot help.', }, { pattern: /\b(unfortunately|sadly),? i('m| am) (unable|not able)/i, feedback: 'No theatrical apologies. State the constraint, then offer the next step the customer can take.', },];
export class BrandVoiceGuardrail implements Processor { id = 'brand-voice-guardrail';
async processOutputStep({ text, abort, retryCount, finishReason, messageList, }: Parameters<NonNullable<Processor['processOutputStep']>>[0]) { if (finishReason === 'tool-calls' || !text) return messageList;
const issues: string[] = [];
if (text.length < MIN_USEFUL_CHARS) { issues.push( 'Response is too short to be useful to the customer — expand with concrete steps.', ); }
for (const { pattern, feedback } of VOICE_VIOLATIONS) { if (pattern.test(text)) issues.push(feedback); }
if (issues.length > 0 && retryCount < 3) { abort(issues.join(' '), { retry: true, metadata: { processor: this.id, issues }, }); }
return messageList; }}Cuatro decisiones para resaltar.
El early return es clave. Los pasos que solo produjeron una tool call no tienen texto. Si igual les corrés los chequeos de texto, vas a tener falsos positivos que reintentan para siempre.
abort es más que “parar”. Llamado con { retry: true }, el paso se reinicia y el string de reason se inyecta en el contexto del modelo como una corrección. Tratá esos strings como si fueran prompts — porque lo son.
El presupuesto de reintentos tiene dos límites. Uno dentro del processor (retryCount < 3) y otro a nivel agent (maxProcessorRetries: 3). También limito adentro del processor porque depender solo del tope del agent convierte un guardrail roto en un comebolas silencioso dentro de un loop más largo.
Los patrones son regex, no jueces LLM. Los output processors corren en cada paso. Un guardrail lento se acumula. Dejá los chequeos semánticos para los scorers, que corren de manera asíncrona después de que termina la conversación.
Guardrail custom #2: promesas no autorizadas
La voz de marca es criterio. Esto otro es una regla de negocio dura.
Los agents de soporte hablan con clientes sobre dinero — reembolsos, créditos, términos de SLA. Ninguna de esas decisiones le corresponde al LLM. Le corresponden a un humano con autoridad. El trabajo del modelo es triagear y escalar.
import type { Processor } from '@mastra/core/processors';
const COMMITMENT_PATTERNS = [ /\b(refund|credit|reimburse|chargeback)\b/i, /\b(guarantee[ds]?|promise|commit) (?:that|to|you)\b/i, /\b(100%|always|never) (?:uptime|available|working)\b/i, /\bwe will (?:waive|comp|discount|cancel)\b/i, /\b(SLA|service level agreement)\b/i,];
export class UnauthorizedPromiseGuardrail implements Processor { id = 'unauthorized-promise-guardrail';
async processOutputStep({ text, abort, retryCount, finishReason, messageList, }: Parameters<NonNullable<Processor['processOutputStep']>>[0]) { if (finishReason === 'tool-calls' || !text) return messageList;
const triggered = COMMITMENT_PATTERNS.filter((p) => p.test(text)); if (triggered.length === 0) return messageList;
if (retryCount < 2) { abort( 'You made a commitment the support agent is not authorized to make ' + '(refund, credit, guarantee, or SLA promise). Do not commit on the company\'s behalf — ' + 'call the escalateToHuman tool with a precise summary so a human agent can approve.', { retry: true, metadata: { processor: this.id, patterns: triggered.map(String) }, }, ); }
abort( 'This request needs approval from a human support agent. It has been flagged for escalation.', { metadata: { processor: this.id, patterns: triggered.map(String) } }, ); return messageList; }}Lo importante: el mensaje del reintento no dice solo “no hagás eso”. Le dice al modelo qué hacer en su lugar — llamar a escalateToHuman. Esa tool vive en el toolbelt del agent:
export const escalateToHuman = createTool({ id: 'escalate-to-human', description: 'Escalate the conversation to a human support agent. Use when the customer ' + 'requests a refund, account changes, contract renegotiation, or any commitment ' + 'beyond providing information from the knowledge base.', inputSchema: z.object({ reason: z.string().min(10), urgency: z.enum(['low', 'normal', 'high']), summary: z.string(), }), // ...});El patrón: un processor atrapa al modelo haciendo lo incorrecto y lo redirige a la tool correcta. Después de un reintento, el modelo normalmente entiende. El cliente termina con un ID de ticket (“derivado a nuestro equipo, ticket T-XYZ, respuesta en ~12 min”) en vez de un rechazo genérico.
Si después de dos reintentos el modelo sigue sin escalar, el processor hace un hard abort con un mensaje seguro de cara al público. Ese tercer camino importa — sin él, un modelo con bugs podría quemar todo el presupuesto de reintentos en el mismo error.
Performance: batching y paralelismo
Un stack de cinco guardrails puede duplicar la latencia de cada paso. Cómo mantenerlos rápidos:
Truco 1: lastMessageOnly: true. Sin esto, cada guardrail re-escanea el historial completo en cada paso. Con esto, solo el último mensaje. En conversaciones largas la diferencia es 10x en llamadas al clasificador.
Truco 2: modelos clasificadores más chicos para los guardrails. El agent principal puede ser un modelo de 120B; los clasificadores de los guardrails no tienen por qué. Un clasificador chico hecho a propósito (Llama Prompt-Guard, gpt-oss-safeguard) hace el mismo trabajo ~5x más rápido y barato. En este ejemplo yo corro todo sobre el modelo principal por simplicidad — antes de escalar, conviene meter uno más chico.
Truco 3: BatchPartsProcessor. Los agents en streaming emiten decenas de chunks de text-delta por segundo. Correr un guardrail respaldado por LLM en cada uno es suicidio. BatchPartsProcessor junta chunks y los emite en grupos:
outputProcessors: [ new BatchPartsProcessor({ batchSize: 10, maxWaitTime: 150 }), // todo guardrail abajo de esta línea ve batches de ~10 chunks new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact' }),],Siempre va antes de cualquier output processor caro.
Truco 4: processors en paralelo dentro de un workflow. Varios guardrails que solo hacen block (sin mutar) son independientes y pueden correr juntos. Se envuelven en un workflow con .parallel() y se pasa eso como un solo “processor”:
import { createWorkflow, createStep } from '@mastra/core/workflows';import { ProcessorStepSchema, PIIDetector, ModerationProcessor } from '@mastra/core/processors';
const outputGuardrails = createWorkflow({ id: 'output-guardrails', inputSchema: ProcessorStepSchema, outputSchema: ProcessorStepSchema,}) .parallel([ createStep(new PIIDetector({ strategy: 'redact' })), createStep(new ModerationProcessor({ strategy: 'block' })), ]) .map(async ({ inputData }) => inputData['processor:pii-detector']) .commit();El paso .map elige qué rama propaga su salida hacia adelante. Si tenés processors que mutan (redact), mapeás a esa rama.
No conviene meterse con esto hasta tener al menos tres guardrails independientes respaldados por LLM. Por debajo de eso, el overhead del workflow no compensa.
Para qué no sirven los processors
Los processors corren sincrónicamente adentro del loop del agent. Son la herramienta correcta para chequeos semánticos rápidos. Son la incorrecta para:
Evaluación cara basada en LLM. Juzgar la calidad de las citas con un modelo grande va en un scorer (asíncrono, muestreado, no bloquea el loop). Meter una llamada al LLM adentro de processOutputStep duplica latencia y costo en cada paso.
Side effects. No mandés notificaciones, no actualicés bases de datos, no llamés a APIs externas adentro de un processor. Si el paso se reintenta, el processor se vuelve a ejecutar y disparás el side effect dos veces. Los side effects van en el execute de la tool o en hooks post-ejecución. Excepción: los callbacks onViolation, que están explícitamente pensados como fire-and-forget para logging y paginado.
Validación estructural. Los schemas de input de tus tools ya lo hacen. Confiá en la capa de schemas de Mastra; no la reimplementés.
La regla: rápido, semántico, sobre el razonamiento del modelo — es un processor. Lento, caro, o un side effect — no lo es.
El stack de producción completo
Para el agent de soporte, de punta a punta:
export const supportAgent = new Agent({ id: 'support-agent', name: 'Support Agent', instructions: `...`, model: 'groq/openai/gpt-oss-120b', tools: { escalateToHuman }, memory: new Memory({ storage: new LibSQLStore({ id: 'support-storage', url: 'file:./mastra.db' }), options: { lastMessages: 20 }, }), inputProcessors: [ new UnicodeNormalizer({ stripControlChars: true, collapseWhitespace: true, trim: true }), new PromptInjectionDetector({ model: GUARDRAIL_MODEL, strategy: 'rewrite', threshold: 0.8, lastMessageOnly: true }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'mask', lastMessageOnly: true }), new ModerationProcessor({ model: GUARDRAIL_MODEL, strategy: 'block', threshold: 0.7, lastMessageOnly: true }), new CostGuardProcessor({ maxCost: 2.0, scope: 'thread', window: '24h' }), ], outputProcessors: [ new BatchPartsProcessor({ batchSize: 10, maxWaitTime: 150 }), new PIIDetector({ model: GUARDRAIL_MODEL, strategy: 'redact', redactionMethod: 'placeholder' }), new BrandVoiceGuardrail(), new UnauthorizedPromiseGuardrail(), ], maxProcessorRetries: 3, defaultOptions: { maxSteps: 10 },});Cinco input processors, cuatro output processors, un tope de costo, un tope de reintentos. ~30 líneas de config del agent más dos archivos de processors custom. Chico como para entrar en una sola pantalla, completo como para poner enfrente de clientes reales.
El modelo mental: los processors son el sistema inmunológico del harness. Chequeos chicos y rápidos que corren todo el tiempo, con la capacidad de decir “no, intentá de nuevo” antes de que algo malo se propague.
Preguntas frecuentes
¿Cuál es la diferencia entre un processor y un scorer?
Los processors corren sincrónicamente, adentro del loop, en cada paso. Pueden bloquear, reintentar o abortar. Los scorers corren asincrónicamente, después de que termina la ejecución, sobre una muestra de ejecuciones. Los processors moderan la ejecución actual; los scorers alimentan tu loop de feedback de largo plazo. Son complementarios, no alternativas.
¿Puedo usar un processor para modificar el texto de la respuesta, no solo para abortar?
processOutputStep es observar-y-abortar. Pero los processors built-in con strategy: 'redact' o strategy: 'rewrite' sí mutan mensajes — PIIDetector, PromptInjectionDetector, SystemPromptScrubber. Patrón: los built-ins manejan la mutación, los processors custom manejan reglas de negocio y reintentos.
¿Cómo interactúa maxProcessorRetries con maxSteps?
Cada reintento cuenta como un paso. Si maxSteps es 10 y maxProcessorRetries es 3, un guardrail que reintenta tres veces antes de aprobar quema 4 pasos para lo que debería ser 1. Dimensioná maxSteps con los reintentos en mente.
¿Qué pasa si abort se llama pero no quedan reintentos?
retryCount >= maxProcessorRetries + abort(message, { retry: true }) se convierte en un hard abort — la ejecución termina con tu mensaje como razón del fallo. Manejá el caso de “se acabaron los reintentos” de forma explícita (como hace UnauthorizedPromiseGuardrail) en vez de depender de este comportamiento implícito. Es más fácil de rastrear después.
¿Los input processors corren en cada paso o solo en el primer mensaje?
processInput corre una vez al inicio. processInputStep corre en cada paso. Los built-in como PromptInjectionDetector y PIIDetector usan processInput, así que solo inspeccionan el mensaje original del usuario. CostGuardProcessor usa processInputStep porque los chequeos de presupuesto tienen que dispararse antes de cada llamada al modelo. Leé el código fuente para saber cuál usa cuál.
¿Cómo detecto en el cliente una respuesta bloqueada?
Para agent.generate(), chequeá result.tripwire y result.finishReason === 'other'. Para agent.stream(), escuchá chunk.type === 'tripwire' en fullStream. Ambos exponen processorId y reason, así que podés ramificar la UI según qué guardrail se disparó.
Cierre
El patrón de frontera es donde todos empiezan. Los processors son lo que se agrega cuando ya viste a tu agent prometer con seguridad un reembolso que no puede dar, quemar ocho pasos en un loop, o filtrarle a un cliente su propio email — y querés que esos modos de fallo no vuelvan a llegar al usuario.
En el próximo episodio: tools MCP, y por qué el string de descripción de una tool es el string más importante de todo tu harness.
Si estás construyendo algo por acá, me encontrás en X.