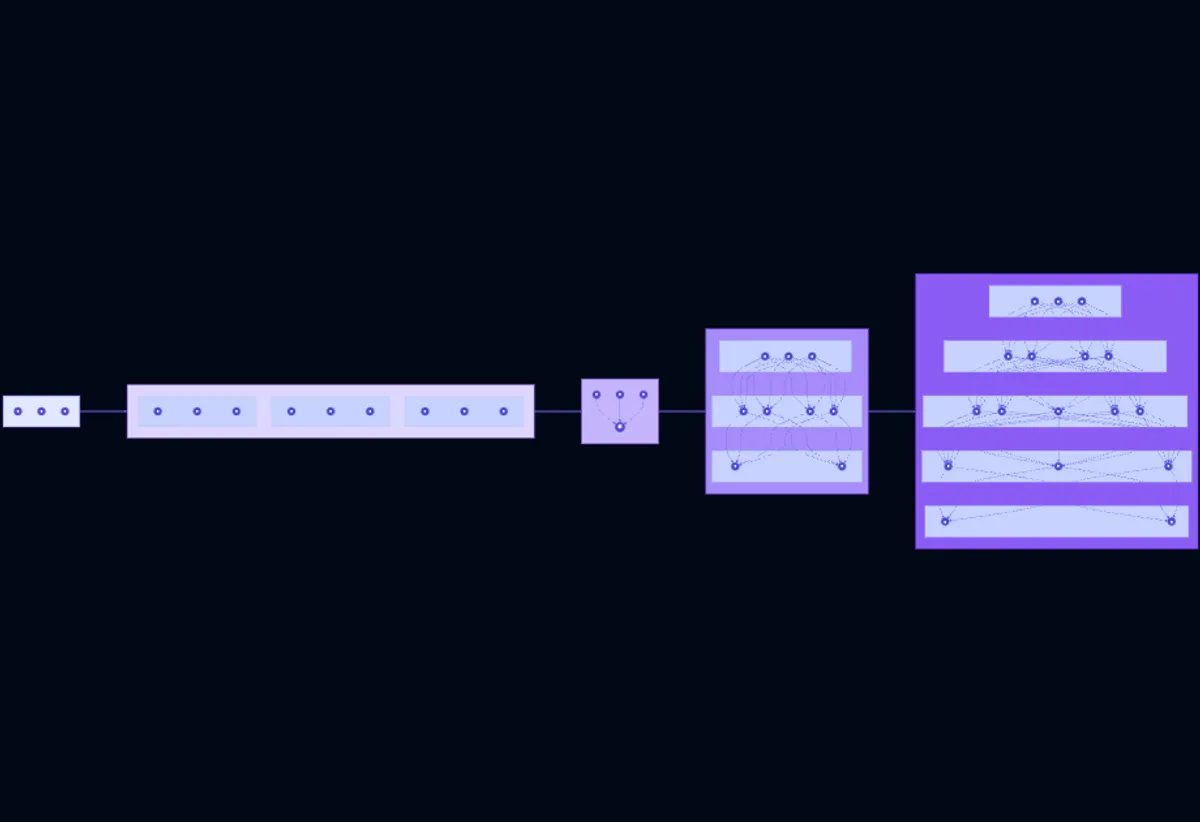
Fundamentos de la IA: De Vectores a Redes Neuronales
Aviso: Todavía estoy aprendiendo algunos de los conceptos tratados en este artículo, y fue escrito con la ayuda de IA. Como resultado, puede contener inexactitudes o errores. Si encontrás algún error, no dudes en contactarme para que pueda corregirlo.
La inteligencia artificial moderna se construye sobre una base matemática que puede parecer intimidante al principio, pero cuyos conceptos centrales son sorprendentemente accesibles. Esta guía completa te llevará a través de cada bloque de construcción, mostrando cómo se conectan y culminan en las arquitecturas sofisticadas que impulsan los sistemas de IA actuales.
El Resumen del Viaje
Imagina comenzar con un lenguaje simple para representar información—vectores, que son solo listas ordenadas de números, y matrices, que transforman estas listas de una forma a otra. Estos objetos matemáticos se convirtieron en nuestro conjunto de herramientas para representar todo: imágenes como vectores de píxeles, palabras como vectores de significado y secuencias enteras como transformaciones de matrices. Cada producto punto entre vectores nos dice qué tan similares son dos cosas—como comparar “gato” y “perro”—y cada multiplicación de matrices remodela la información, permitiéndonos construir transformaciones cada vez más sofisticadas paso a paso.
Con esta base, descubrimos cómo hacer que estos sistemas matemáticos aprendan por sí mismos. Las redes neuronales emergieron como cadenas de estas transformaciones, donde cada capa aprende patrones cada vez más abstractos: las primeras capas podrían detectar bordes, mientras que las capas posteriores reconocen objetos enteros. La magia del aprendizaje ocurre a través de gradientes—brújulas matemáticas que apuntan en la dirección de mejora. Al seguir estos gradientes hacia abajo (descenso de gradiente), la red ajusta continuamente sus millones de parámetros para reducir sus errores, descubriendo gradualmente patrones que ningún humano podría programar explícitamente.
Pero aún faltaba una pieza: cómo representar símbolos discretos como palabras de una manera que capturara su significado. Esto llevó a los embeddings—aprender a mapear palabras en vectores densos donde significados similares se agrupan en el espacio. De repente, la aritmética con palabras reveló relaciones: “rey” menos “hombre” más “mujer” es aproximadamente “reina”. Este avance desbloqueó los mecanismos de atención, que permiten a los modelos enfocarse dinámicamente en diferentes partes de su entrada al producir cada pieza de salida—como prestar atención a “gato” al traducir “cat”, en lugar de intentar recordar todo en un resumen fijo.
Finalmente, la atención evolucionó en transformers, que revolucionaron la IA al procesar secuencias enteras en paralelo a través de auto-atención. Cada posición consulta a las demás (“¿qué información necesito?”), recibe respuestas ponderadas por relevancia y las combina en representaciones ricas y conscientes del contexto. Esta arquitectura elegante—construida completamente a partir de las matemáticas simples de vectores, matrices, gradientes y atención—impulsa los sistemas de IA más capaces de hoy, desde modelos de lenguaje que escriben poesía hasta generadores de imágenes que crean arte. El viaje desde el álgebra lineal básica hasta los transformers basados en atención revela una historia hermosa: capacidades profundas que emergen de fundamentos matemáticos cuidadosamente compuestos.
Progresaremos a través de cuatro fases:
- Fundamentos Matemáticos: Álgebra lineal, probabilidad y cálculo
- Optimización: Funciones de pérdida y descenso de gradiente
- Redes Neuronales: Perceptrones, activaciones y retropropagación
- Arquitecturas Avanzadas: Atención, transformers y embeddings
Al final, tendrás una comprensión completa de cómo estas piezas se ajustan juntas para crear sistemas que pueden aprender de datos y realizar tareas notables.
Fase 1: Introducción
Introducción
La IA moderna y el aprendizaje profundo se construyen sobre una base de matemáticas que puede parecer intimidante al principio, pero los conceptos centrales son sorprendentemente accesibles. Esta serie te guiará a través de los fundamentos matemáticos, mostrando cómo cada pieza se conecta con la siguiente, hasta llegar a las arquitecturas sofisticadas que impulsan los sistemas de IA actuales.
Fase 1: El Lenguaje Matemático
Notación y Vocabulario
Antes de sumergirnos en las matemáticas, establezcamos un vocabulario común. En el aprendizaje automático y las redes neuronales, encontrarás frecuentemente:
- Escalares: Números únicos (por ejemplo, )
- Vectores: Listas ordenadas de números, denotadas como
- Matrices: Arreglos 2D de números, denotados como
- Funciones: Mapeos de entradas a salidas,
- Parámetros: Valores que aprendemos durante el entrenamiento (pesos, sesgos)
Esta notación se convierte en nuestro lenguaje compartido para describir cálculos en redes neuronales.
Álgebra Lineal: Vectores y Matrices
El álgebra lineal es el caballo de batalla del aprendizaje automático. Cada cálculo en una red neuronal puede expresarse como operaciones sobre vectores y matrices.
Los vectores representan puntos de datos. Por ejemplo, una imagen con 784 píxeles puede representarse como un vector .
Las matrices representan transformaciones. Una matriz de pesos transforma una entrada -dimensional en una salida -dimensional.
Operaciones clave:
- Suma de vectores:
- Multiplicación por escalar:
- Producto punto:
- Multiplicación de matrices:
El producto punto es particularmente importante—mide la similitud entre vectores y es la operación fundamental en las redes neuronales.
Por qué importa: Las redes neuronales transforman datos a través de secuencias de transformaciones lineales (multiplicaciones de matrices). Comprender estas operaciones nos ayuda a entender qué está aprendiendo la red.
Probabilidad Básica: Variables Aleatorias y Distribuciones
Las redes neuronales operan en un mundo de incertidumbre. La teoría de la probabilidad nos proporciona herramientas para modelar y razonar sobre esta incertidumbre.
Variables aleatorias: Variables cuyos valores dependen de resultados aleatorios. Por ejemplo, podría representar los valores de píxeles en una imagen, que varían aleatoriamente según el contenido de la imagen.
Distribuciones: Funciones que describen la probabilidad de diferentes resultados:
- Distribución de Bernoulli: (resultados binarios)
- Distribución gaussiana (normal): (curva de campana)
Conceptos clave:
- Valor esperado: (el valor promedio)
- Varianza: (dispersión de la distribución)
- Independencia: Dos eventos son independientes si
Por qué importa: Muchas salidas de redes neuronales son probabilísticas (por ejemplo, probabilidades de clasificación). También usamos la probabilidad para medir la incertidumbre, regularizar modelos y generar salidas diversas.
Derivadas y Gradientes
Para entrenar redes neuronales, necesitamos optimizar funciones. Las derivadas nos dicen cómo cambian las funciones.
Derivada: La tasa de cambio de una función en un punto:
Para una función , la derivada es . Esto nos dice que en , la función está aumentando a una tasa de 6.
Gradiente: La generalización de las derivadas a funciones multivariables. Para , el gradiente es:
El gradiente apunta en la dirección de mayor ascenso—esto es crucial para la optimización.
Ejemplo: Para , . En el punto , el gradiente es , apuntando en la dirección de mayor aumento.
Regla de la cadena: Cuando las funciones están compuestas, podemos calcular derivadas usando:
Esta regla es la columna vertebral matemática de la retropropagación, que cubriremos en la Fase 3.
Por qué importa: Las redes neuronales aprenden ajustando parámetros para minimizar una función de pérdida. El gradiente nos dice en qué dirección ajustar cada parámetro para reducir la pérdida.
Conectando los Puntos
Estos tres pilares—álgebra lineal, probabilidad y cálculo—trabajan juntos en las redes neuronales:
- Álgebra lineal proporciona la estructura para representar y transformar datos
- Probabilidad modela la incertidumbre y guía los objetivos de aprendizaje
- Cálculo (gradientes) nos permite optimizar la red
En la siguiente fase, veremos cómo estos conceptos se combinan en el descenso de gradiente y las funciones de pérdida, preparando el escenario para entender cómo las redes neuronales realmente aprenden.
Fase 2:
En la Fase 1, construimos el conjunto de herramientas matemáticas: álgebra lineal para la transformación de datos, probabilidad para modelar la incertidumbre y cálculo para entender el cambio. Ahora veremos cómo estas herramientas se combinan para crear el mecanismo de aprendizaje en el corazón de todas las redes neuronales.
Funciones de Pérdida: Midiendo el Error
Para aprender, una red neuronal necesita saber qué tan bien lo está haciendo. Una función de pérdida (o función de costo) cuantifica el error entre las predicciones y los valores verdaderos.
Funciones de Pérdida Comunes
Error cuadrático medio (MSE - Mean Squared Error): Para problemas de regresión
Donde es el valor verdadero y es el valor predicho. La diferencia se eleva al cuadrado para penalizar más fuertemente los errores grandes.
Pérdida de entropía cruzada (CE - Cross-Entropy): Para problemas de clasificación
Donde es el número de clases, es la etiqueta verdadera (codificada en one-hot) y es la probabilidad predicha. Esta pérdida penaliza fuertemente las predicciones incorrectas con confianza.
Ejemplo: Si estamos clasificando imágenes como “gato”, “perro” o “pájaro”, y la etiqueta verdadera es “gato” (), una predicción de tendría una pérdida baja, mientras que tendría una pérdida alta.
Por qué importa: La función de pérdida es nuestro objetivo. Todo en el entrenamiento se trata de minimizar esta función. Una buena función de pérdida refleja con precisión lo que nos importa en el mundo real.
Descenso de Gradiente: El Algoritmo de Aprendizaje
Una vez que tenemos una función de pérdida, ¿cómo la minimizamos? La respuesta es el descenso de gradiente.
Intuición
Imagina que estás en una montaña en niebla espesa. Quieres llegar al punto más bajo (el valle), pero no puedes ver el terreno. ¿Qué haces?
- Siente el suelo a tu alrededor para determinar en qué dirección la pendiente desciende
- Da un paso en esa dirección
- Repite hasta llegar al fondo
Esto es el descenso de gradiente: el paisaje de pérdida es nuestra montaña, el gradiente apunta cuesta abajo, y cada paso es una actualización de parámetros.
El Algoritmo
Para un vector de parámetros (todos los pesos y sesgos en la red):
- Calcular gradiente:
- Actualizar parámetros:
- Repetir hasta la convergencia
La tasa de aprendizaje (eta) controla el tamaño del paso:
- Muy pequeña: El aprendizaje es muy lento
- Muy grande: Podríamos pasar por alto o divergir
Ejemplo: Caso Unidimensional
Sea . Queremos encontrar que minimice esto.
El gradiente es:
Comenzando en con tasa de aprendizaje :
- Paso 1: Gradiente , actualización:
- Paso 2: Gradiente , actualización:
- Paso 3: Gradiente , actualización:
¡Nos estamos moviendo hacia , el verdadero mínimo!
Descenso de Gradiente Estocástico (SGD)
En la práctica, usamos descenso de gradiente estocástico (Stochastic Gradient Descent, SGD): en lugar de calcular el gradiente sobre todos los datos de entrenamiento, usamos un pequeño lote (mini-batch).
Donde es un lote aleatorio de ejemplos de entrenamiento.
¿Por qué SGD?
- Computacionalmente eficiente (no se necesitan todos los datos para cada actualización)
- Las actualizaciones con ruido ayudan a escapar de mínimos locales
- Funciona mejor con conjuntos de datos grandes
Optimizadores Avanzados
El entrenamiento moderno rara vez usa SGD puro. Las variantes populares incluyen:
- Momentum: Acumula gradientes pasados para acelerarse a través de regiones planas
- Adam: Combina momentum con tasas de aprendizaje adaptativas
- RMSprop: Adapta tasas de aprendizaje por parámetro
Estos se construyen sobre el mismo principio de descenso de gradiente pero usan el gradiente de manera más inteligente.
La Importancia de los Gradientes en el Entrenamiento de Redes
Los gradientes son el flujo vital del entrenamiento de redes neuronales. Entendamos por qué.
Los Gradientes Guían el Aprendizaje
Cada componente de gradiente nos dice:
- Cuánto cambiaría la pérdida si aumentáramos por una pequeña cantidad
- En qué dirección mover para reducir la pérdida
Un gradiente positivo grande significa “disminuir este parámetro para reducir la pérdida”, mientras que un gradiente negativo grande significa “aumentar este parámetro para reducir la pérdida”.
Gradientes Desvanecientes y Explotantes
Dos problemas comunes en redes profundas:
Gradientes desvanecientes: En redes muy profundas, los gradientes pueden volverse extremadamente pequeños, haciendo que las primeras capas aprendan muy lentamente. Este fue un gran desafío en las primeras redes neuronales.
Gradientes explotantes: Los gradientes pueden volverse extremadamente grandes, causando que los parámetros cambien drásticamente y que el entrenamiento se vuelva inestable.
Las soluciones incluyen:
- Inicialización cuidadosa (por ejemplo, inicialización de Xavier, He)
- Funciones de activación con gradientes bien comportados (las veremos en la Fase 3)
- Recorte de gradientes (gradient clipping)
- Conexiones residuales (conexiones de omisión)
Flujo de Gradiente a Través de la Red
En una red profunda, los gradientes fluyen hacia atrás desde la salida hasta la entrada:
Entrada → [Capa 1] → [Capa 2] → ... → [Salida] ↑ ↑ ↑ Gradiente Gradiente Gradiente (comienza aquí)Si los gradientes se desvanecen temprano, las primeras capas (que a menudo aprenden características fundamentales) no reciben señales de entrenamiento útiles. Si los gradientes explotan, el entrenamiento se vuelve inestable.
Por qué importa: Entender el flujo de gradientes nos ayuda a diseñar mejores arquitecturas. Los avances modernos como las redes residuales fueron motivados específicamente para mejorar el flujo de gradientes.
Poniéndolo Todo Junto
Ahora tenemos una imagen completa del bucle de aprendizaje:
- Paso hacia adelante: Calcular predicciones usando los parámetros actuales
- Calcular pérdida: Medir el error usando una función de pérdida
- Paso hacia atrás: Calcular gradientes de la pérdida con respecto a todos los parámetros
- Actualizar parámetros: Mover los parámetros en la dirección opuesta de los gradientes
- Repetir
Este bucle, aplicado miles o millones de veces, es cómo las redes neuronales aprenden de los datos. En la Fase 3, nos sumergiremos en la arquitectura de la red neuronal misma—cómo las neuronas, las capas y las funciones de activación trabajan juntas para crear potentes aproximadores de funciones.
Fase 3:
En las Fases 1 y 2, cubrimos la maquinaria matemática: álgebra lineal para transformaciones, probabilidad para modelar y descenso de gradiente para optimización. Ahora veremos cómo estas piezas se ensamblan en redes neuronales—los aproximadores de funciones que pueden aprender patrones complejos de los datos.
¿Qué es una Red Neuronal?
En su núcleo, una red neuronal es una función matemática compuesta de funciones más simples. Toma entradas, aplica una serie de transformaciones y produce salidas. La “magia” es que las transformaciones están parametrizadas, y aprendemos esos parámetros de los datos.
Matemáticamente: Una red neuronal calcula donde es la entrada y representa todos los parámetros aprendibles.
Conceptualmente: Es un grafo computacional donde los nodos realizan operaciones y los bordes representan el flujo de datos.
El Perceptrón: El Bloque de Construcción
El perceptrón es la unidad de red neuronal más simple—una sola neurona artificial.
Estructura
Un perceptrón toma entradas y produce una salida:
Entradas: x₁, x₂, ..., xₙ ↓ ↓ ↓Pesos: w₁, w₂, ..., wₙ ↓ ↓ ↓ Suma: z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b ↓ Activación: a = σ(z) ↓ Salida: y = aMatemáticamente:
Donde:
- es el vector de pesos
- es el sesgo (bias, permite desplazar la función de activación)
- es una función de activación
- se llama “pre-activación”
Intuición Geométrica
El cálculo es un hiperplano en . El perceptrón decide en qué lado de este hiperplano cae la entrada.
Para entradas 2D :
- El límite de decisión es la línea
- Los puntos por encima de la línea tienen , por debajo tienen
Limitaciones de los Perceptrones Individuales
Un solo perceptrón solo puede aprender funciones linealmente separables. No puede resolver el problema XOR, que requiere un límite de decisión no lineal.
Solución: Apilar múltiples perceptrones para crear un perceptrón multicapa (MLP - Multi-Layer Perceptron).
Redes de Avance (Feed-Forward)
Una red de avance (o perceptrón multicapa) consiste en capas de perceptrones conectadas secuencialmente.
Arquitectura
Capa de Entrada Capa Oculta 1 Capa Oculta 2 Capa de Salida [x₁] ──────► [h₁₁] ──────► [h₂₁] ──────► [y₁] [x₂] ──────► [h₁₂] ──────► [h₂₂] ──────► [y₂] [x₃] ──────► [h₁₃] ──────► [h₂₃] ──────► [y₃] ... ...Cada capa transforma la representación:
Donde (entrada) y (salida).
¿Por qué múltiples capas?: Cada capa aprende características cada vez más abstractas. En el reconocimiento de imágenes, las primeras capas podrían detectar bordes, las capas medias detectan formas, y las capas posteriores detectan objetos.
Teorema de Aproximación Universal
Un resultado teórico notable: Una red de avance con una sola capa oculta y activación no lineal puede aproximar cualquier función continua con precisión arbitraria (dadas suficientes neuronas).
Esto significa que las redes neuronales son aproximadores de funciones increíblemente flexibles—pueden aprender prácticamente cualquier mapeo de entradas a salidas dada suficiente capacidad.
Funciones de Activación: Agregando No-Linealidad
Sin funciones de activación, una red multicapa sería solo una serie de transformaciones lineales, que podrían colapsarse en una sola transformación lineal. Las funciones de activación introducen no-linealidad, permitiendo que la red aprenda patrones complejos y no lineales.
Sigmoide
Propiedades:
- Salida en (interpretable como probabilidad)
- Gradiente suave:
- Históricamente popular pero sufre de gradientes desvanecientes
Caso de uso: Salida de clasificación binaria
ReLU (Unidad Lineal Rectificada)
Propiedades:
- Simple: si , si no
- Activación dispersa (muchas neuronas producen cero)
- Evita el gradiente desvaneciente (el gradiente es 1 para entradas positivas)
- Computacionalmente eficiente
Caso de uso: Capas ocultas en la mayoría de las redes modernas
Por qué ReLU Ganó
La simplicidad de ReLU y la falta de problemas de gradiente desvaneciente la convirtieron en la opción predeterminada para capas ocultas. Variantes como Leaky ReLU y ELU abordan el problema de “ReLU muerto” (neuronas que nunca se activan).
El Paso hacia Adelante: Haciendo Predicciones
El paso hacia adelante calcula la salida de la red dadas las entradas.
Paso a paso:
- La entrada entra en la primera capa
- Para cada capa a : a. Calcular pre-activación: b. Aplicar activación:
- La salida es la predicción
Ejemplo: Para una red con una capa oculta:
# Paso hacia adelantez_hidden = W_hidden @ x + b_hiddenh_hidden = relu(z_hidden)z_output = W_output @ h_hidden + b_outputy_pred = sigmoid(z_output) # Para clasificación binariaRetropropagación: Aprendiendo de Errores
La retropropagación (backpropagation) es el algoritmo que calcula gradientes eficientemente para redes neuronales. Aplica la regla de la cadena recursivamente desde la salida hasta la entrada.
La Regla de la Cadena en Acción
Para una red simple con una capa oculta:
Para encontrar , encadenamos a través del cálculo:
Algoritmo Simplificado de Retropropagación
- Paso hacia adelante: Almacenar todos los valores intermedios (, )
- Gradiente de salida: Calcular
- Paso hacia atrás: Para cada capa a :
- Gradientes de parámetros:
Eficiencia Computacional
La clave de la retropropagación es que calculamos gradientes en tiempo donde es el número de parámetros, en lugar de para la diferenciación numérica ingenua. Esto hace factible el entrenamiento de redes grandes.
Ejemplo: Calculando un Gradiente
Para una sola neurona con entrada , peso , sesgo , activación sigmoide y pérdida MSE:
- Hacia adelante: , ,
- Hacia atrás:
Esto nos dice exactamente cómo ajustar para reducir la pérdida.
Poniéndolo Todo Junto: Bucle de Entrenamiento
Ahora tenemos todas las piezas:
# Inicializar parámetrosW_hidden, b_hidden = initialize_weights()W_output, b_output = initialize_weights()
for epoch in range(num_epochs): for batch in data_loader: # Paso hacia adelante z_hidden = W_hidden @ x + b_hidden h_hidden = relu(z_hidden) z_output = W_output @ h_hidden + b_output y_pred = sigmoid(z_output)
# Calcular pérdida loss = binary_cross_entropy(y, y_pred)
# Paso hacia atrás (retropropagación) grad_output = (y_pred - y) * y_pred * (1 - y_pred) grad_W_output = grad_output @ h_hidden.T grad_b_output = grad_output
grad_hidden = (W_output.T @ grad_output) * (z_hidden > 0) grad_W_hidden = grad_hidden @ x.T grad_b_hidden = grad_hidden
# Actualizar parámetros (descenso de gradiente) W_output -= learning_rate * grad_W_output b_output -= learning_rate * grad_b_output W_hidden -= learning_rate * grad_W_hidden b_hidden -= learning_rate * grad_b_hiddenEn la Fase 4, exploraremos cómo estas redes básicas evolucionaron hacia las arquitecturas sofisticadas que impulsan la IA moderna, incluyendo mecanismos de atención y transformers.
Fase 4:
Hemos cubierto los fundamentos: álgebra lineal, probabilidad, cálculo, descenso de gradiente y redes neuronales básicas. Ahora llegamos a las arquitecturas que han revolucionado la IA—mecanismos de atención y transformers. Estos conceptos, combinados con embeddings, impulsan modelos como GPT, BERT y la generación actual de sistemas de IA.
Embeddings: Representando Significado como Vectores
Antes de entender la atención, necesitamos entender cómo representamos entradas discretas (como palabras) como vectores continuos que las redes neuronales pueden procesar.
De One-Hot a Vectores Densos
Codificación one-hot: Representar cada palabra como un vector disperso donde solo una posición es 1.
"gato" = [1, 0, 0, 0, ...]"perro" = [0, 1, 0, 0, ...]"pájaro" = [0, 0, 1, 0, ...]Problemas: Alta dimensionalidad, noción de similitud, ninguna relación entre palabras.
Word embeddings: Aprender vectores densos de baja dimensionalidad donde la similitud semántica corresponde a similitud geométrica.
"gato" ≈ [0.2, -0.5, 0.8, 0.1, ...]"perro" ≈ [0.3, -0.4, 0.7, 0.2, ...]"pájaro" ≈ [0.9, 0.3, -0.2, 0.5, ...]Ahora “gato” y “perro” tienen vectores similares (están semánticamente relacionados), mientras que “pájaro” es diferente.
Por Qué Funcionan los Embeddings
Las palabras que aparecen en contextos similares deberían tener significados similares. Al aprender a predecir palabras del contexto (o viceversa), capturamos automáticamente relaciones semánticas.
Propiedad famosa: La aritmética vectorial captura relaciones:
rey - hombre + mujer ≈ reina¡La dirección de “hombre” a “mujer” es similar a la dirección de “rey” a “reina”!
Entrenando Embeddings
Word2Vec: Dos enfoques:
- Skip-gram: Predecir palabras de contexto de la palabra objetivo
- CBOW: Predecir palabra objetivo del contexto
GloVe: Factorizar matriz de co-ocurrencia de palabras
Enfoque moderno: Aprender embeddings como parte del entrenamiento del modelo en lugar de pre-entrenar por separado.
Más Allá de las Palabras
Los embeddings se extienden más allá de las palabras:
- Embeddings de caracteres: Para información de subpalabras
- Embeddings posicionales: Para el orden de secuencias
- Embeddings de oraciones: Para documentos completos
- Embeddings multimodales: Para imágenes, audio, etc.
Atención: Qué Es y Por Qué Importa
Los mecanismos de atención permiten a los modelos enfocarse en partes relevantes de la entrada al producir cada parte de la salida. Este fue un avance que resolvió las limitaciones de los modelos secuencia-a-secuencia.
El Problema de las Representaciones Fijas
Antes de la atención, los modelos de secuencia (como las RNNs) comprimían una secuencia de entrada completa en un solo vector de tamaño fijo:
Entrada: "The cat sat on the mat"↓ (codificar oración completa)Vector fijo: [0.1, -0.3, 0.7, ...]↓ (decodificar)Salida: "El gato se sentó en la alfombra"Problema: Toda la información debe comprimirse en un vector, lo que se convierte en un cuello de botella para secuencias largas.
La Solución de Atención
En lugar de usar un vector fijo, permitir que cada paso de salida mire diferentes partes de la entrada, ponderado por relevancia.
Al generar "El" → Enfocarse en "The"Al generar "gato" → Enfocarse en "cat"Al generar "se" → Enfocarse en "sat"Matemáticamente, para la posición de salida , calculamos una suma ponderada de representaciones de entrada:
Donde es el peso de atención de la posición de salida a la posición de entrada .
Calculando Pesos de Atención
¿Cómo calculamos ? Usamos una función de compatibilidad que mide qué tan bien la posición de entrada se relaciona con la posición de salida .
Atención de producto punto:
Donde:
- es el vector de query (lo que estamos buscando)
- es el vector de key (lo que la entrada ofrece)
- es el vector de value (el contenido real)
El softmax asegura que los pesos sumen 1 (distribución de probabilidad).
Query, Key, Value (Q, K, V) Explicados
El marco Q, K, V es el núcleo de los mecanismos de atención modernos. Desglosémoslo con un ejemplo intuitivo.
Intuición: Analogía de Base de Datos
Piénsalo como una consulta de base de datos:
- Query (Q): Lo que estás buscando
- Key (K): Cómo están indexados los elementos
- Value (V): El contenido real
Base de datos: Key: "nombre", Value: "Ana" Key: "edad", Value: 30 Key: "ciudad", Value: "CDMX"
Query: "nombre"→ Coincidencia: Key "nombre" coincide con Query "nombre"→ Retornar: Value "Ana"En Redes Neuronales
Cada posición de entrada tiene su propia K y V. Cada posición de salida tiene su propia Q. Calculamos la similitud entre Q y todas las K, luego ponderamos las V por estas similitudes.
Q, K, V en Código
def scaled_dot_product_attention(Q, K, V): """ Args: Q: (batch_size, seq_len, d_k) K: (batch_size, seq_len, d_k) V: (batch_size, seq_len, d_v) Returns: output: (batch_size, seq_len, d_v) attention_weights: (batch_size, seq_len, seq_len) """ # Calcular puntuaciones de similitud scores = Q @ K.transpose(-2, -1) # (batch_size, seq_len, seq_len)
# Escalar para prevenir valores de softmax extremadamente grandes scores = scores / np.sqrt(K.shape[-1])
# Aplicar softmax para obtener pesos de atención attention_weights = softmax(scores, axis=-1)
# Ponderar valores por pesos de atención output = attention_weights @ V
return output, attention_weightsPasos clave:
- Calcular Q·K para obtener puntuaciones de similitud
- Escalar por (estabiliza gradientes)
- Aplicar softmax para obtener distribución de probabilidad
- Suma ponderada de V
Atención Multi-Cabezal
En lugar de un conjunto de Q, K, V, usamos múltiples “cabezas” que aprenden diferentes relaciones:
class MultiHeadAttention: def __init__(self, d_model, num_heads): self.d_model = d_model self.num_heads = num_heads self.d_k = d_model // num_heads
# Matrices de proyección aprendibles self.W_Q = initialize_weights((d_model, d_model)) self.W_K = initialize_weights((d_model, d_model)) self.W_V = initialize_weights((d_model, d_model)) self.W_O = initialize_weights((d_model, d_model))
def forward(self, x): batch_size, seq_len, _ = x.shape
# Proyectar a Q, K, V para cada cabeza Q = x @ self.W_Q # (batch, seq_len, d_model) K = x @ self.W_K V = x @ self.W_V
# Dividir en cabezas y remodelar Q = Q.reshape(batch_size, seq_len, self.num_heads, self.d_k) K = K.reshape(batch_size, seq_len, self.num_heads, self.d_k) V = V.reshape(batch_size, seq_len, self.num_heads, self.d_k)
# Transponer a (batch, num_heads, seq_len, d_k) Q = Q.transpose(1, 2) K = K.transpose(1, 2) V = V.transpose(1, 2)
# Calcular atención para cada cabeza scores = Q @ K.transpose(-2, -1) / np.sqrt(self.d_k) attention_weights = softmax(scores, axis=-1) attended = attention_weights @ V
# Concatenar cabezas y proyectar attended = attended.transpose(1, 2).reshape(batch_size, seq_len, self.d_model) output = attended @ self.W_O
return output, attention_weightsCada cabeza puede enfocarse en diferentes tipos de relaciones:
- La cabeza 1 podría enfocarse en la estructura sintáctica
- La cabeza 2 podría enfocarse en la similitud semántica
- La cabeza 3 podría enfocarse en las relaciones posicionales
Transformers: La Arquitectura Solo-Atención
Los transformers reemplazan completamente la recurrencia (RNNs) y la convolución (CNNs) con mecanismos de atención.
Innovaciones Clave
1. Auto-atención: En lugar de atención entre codificador y decodificador, cada posición atiende a todas las demás posiciones en la misma secuencia.
Para cada palabra "gato", calcular pesos de atención con todas las palabras:"gato" atiende a: "The"(0.1), "gato"(0.6), "sat"(0.2), "on"(0.05), "the"(0.03), "mat"(0.02)2. Codificación posicional: Dado que la atención no captura inherentemente el orden, agregamos información de posición:
Estas codificaciones sinusoidales permiten al modelo aprender posiciones relativas.
3. Paralelización: A diferencia de las RNNs que procesan secuencialmente, los transformers procesan todas las posiciones simultáneamente, permitiendo una paralelización masiva en GPUs.
Arquitectura del Transformer
Embedding de Entrada + Codificación Posicional ↓ ┌─────────────────┐ │ Pila de Codificador │ │ (N veces) │ │ │ │ ┌───────────┐ │ │ │ Multi-Head│ │ │ │ Attention │ │ │ └───────────┘ │ │ ↓ │ │ ┌───────────┐ │ │ │ Feed- │ │ │ │ Forward │ │ │ └───────────┘ │ └─────────────────┘ ↓ ┌─────────────────┐ │ Pila de Decodificador │ │ (N veces) │ │ │ │ ┌───────────┐ │ │ │ Masked │ │ │ │ Multi-Head│ │ │ │ Attention │ │ │ └───────────┘ │ │ ↓ │ │ ┌───────────┐ │ │ │ Cross │ │ │ │ Attention│ │ │ └───────────┘ │ │ ↓ │ │ ┌───────────┐ │ │ │ Feed- │ │ │ │ Forward │ │ │ └───────────┘ │ └─────────────────┘ ↓ SalidaCodificador: Procesa la secuencia de entrada y produce representaciones contextuales
Decodificador: Genera la secuencia de salida, atendiendo tanto a la salida del codificador como a los tokens generados previamente
Atención enmascarada: Evita que el decodificador “vea el futuro” durante el entrenamiento (autoregresivo)
Por Qué Funcionan Tan Bien los Transformers
- Dependencias de largo alcance: La atención conecta directamente cualquier dos posiciones, sin importar qué tan lejos estén
- Paralelización: Procesar secuencias completas a la vez, permitiendo entrenamiento en conjuntos de datos masivos
- Interpretabilidad: Los pesos de atención muestran en qué se enfoca el modelo
- Escalabilidad: El rendimiento continúa mejorando con más datos y cómputo
De Transformers a LLMs
Los modelos de lenguaje grandes modernos son esencialmente:
- Transformers solo-decodificador (para generación de texto autoregresiva)
- Entrenados en conjuntos de datos de texto masivos
- Escalados con más parámetros, más datos y más cómputo
La arquitectura que hemos discutido es esencialmente la misma que GPT, BERT y LLaMA—solo escalada.
La Imagen Completa
Hemos rastreado el viaje completo:
- Álgebra lineal: Vectores y matrices representan y transforman datos
- Probabilidad: Modela incertidumbre y define objetivos de aprendizaje
- Cálculo: Los gradientes guían las actualizaciones de parámetros
- Descenso de gradiente: El algoritmo de optimización que aprende parámetros
- Redes neuronales: Aproximadores de funciones parametrizados compuestos de capas
- Perceptrones: Bloques de construcción con pesos, sesgos y activaciones
- Paso hacia atrás/retropropagación: Haciendo predicciones y calculando gradientes
- Activaciones: ReLU y sigmoide introducen no-linealidad
- Embeddings: Símbolos discretos se convierten en vectores continuos significativos
- Atención: Los modelos se enfocan dinámicamente en información relevante
- Q/K/V: Marco para calcular relevancia e importancia
- Transformers: Arquitecturas basadas en atención que procesan secuencias
- IA moderna: Escala estos principios para lograr capacidades notables
Cada concepto se construye sobre los anteriores, creando una base matemática que permite a las máquinas aprender de datos y realizar tareas cada vez más sofisticadas. Comprender estos fundamentos desmitifica la IA y proporciona la intuición para innovar y construir la próxima generación de sistemas inteligentes.
Conclusión
Hemos rastreado el viaje completo desde operaciones matemáticas básicas hasta arquitecturas de IA de vanguardia. Cada concepto se construye sobre los anteriores, creando un marco coherente para entender cómo las máquinas aprenden:
- Álgebra lineal proporciona el lenguaje para representar y transformar datos
- Probabilidad nos ayuda a modelar la incertidumbre y definir qué queremos aprender
- Cálculo (gradientes) nos muestra cómo mejorar nuestros modelos
- Descenso de gradiente es el algoritmo que impulsa el aprendizaje
- Redes neuronales son los aproximadores de funciones flexibles que aprenden de datos
- Mecanismos de atención permiten a los modelos enfocarse en lo importante
- Transformers aprovechan la atención para procesar secuencias eficientemente
Este conocimiento no es solo académico—es la base para construir, entender y mejorar sistemas de IA. Ya sea que estés implementando una red neuronal, depurando un modelo de transformer o diseñando una nueva arquitectura, estos fundamentos te proporcionan la intuición y las herramientas que necesitas.
La próxima vez que uses ChatGPT, generes imágenes con DALL-E o interactúes con cualquier sistema de IA, entenderás la maquinaria matemática trabajando bajo la superficie. Y quizás más importante, estarás equipado para contribuir a la próxima generación de innovaciones en IA.